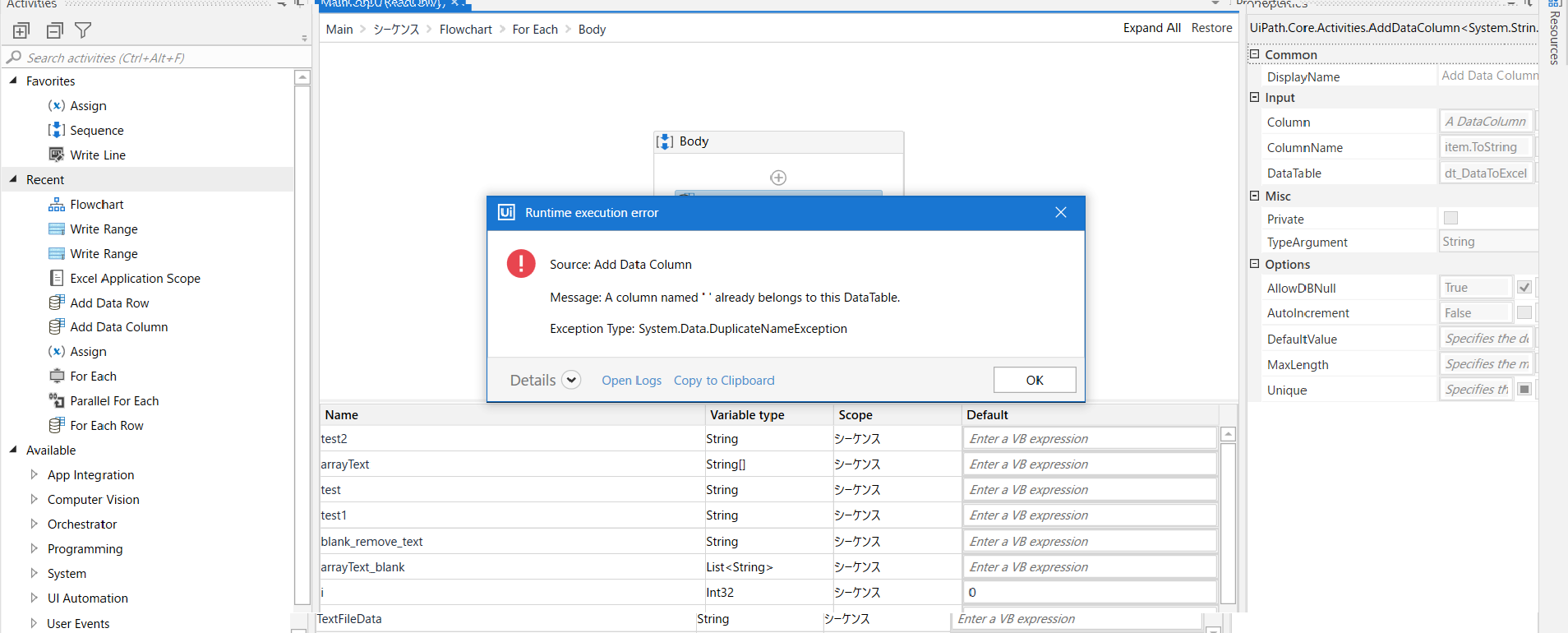
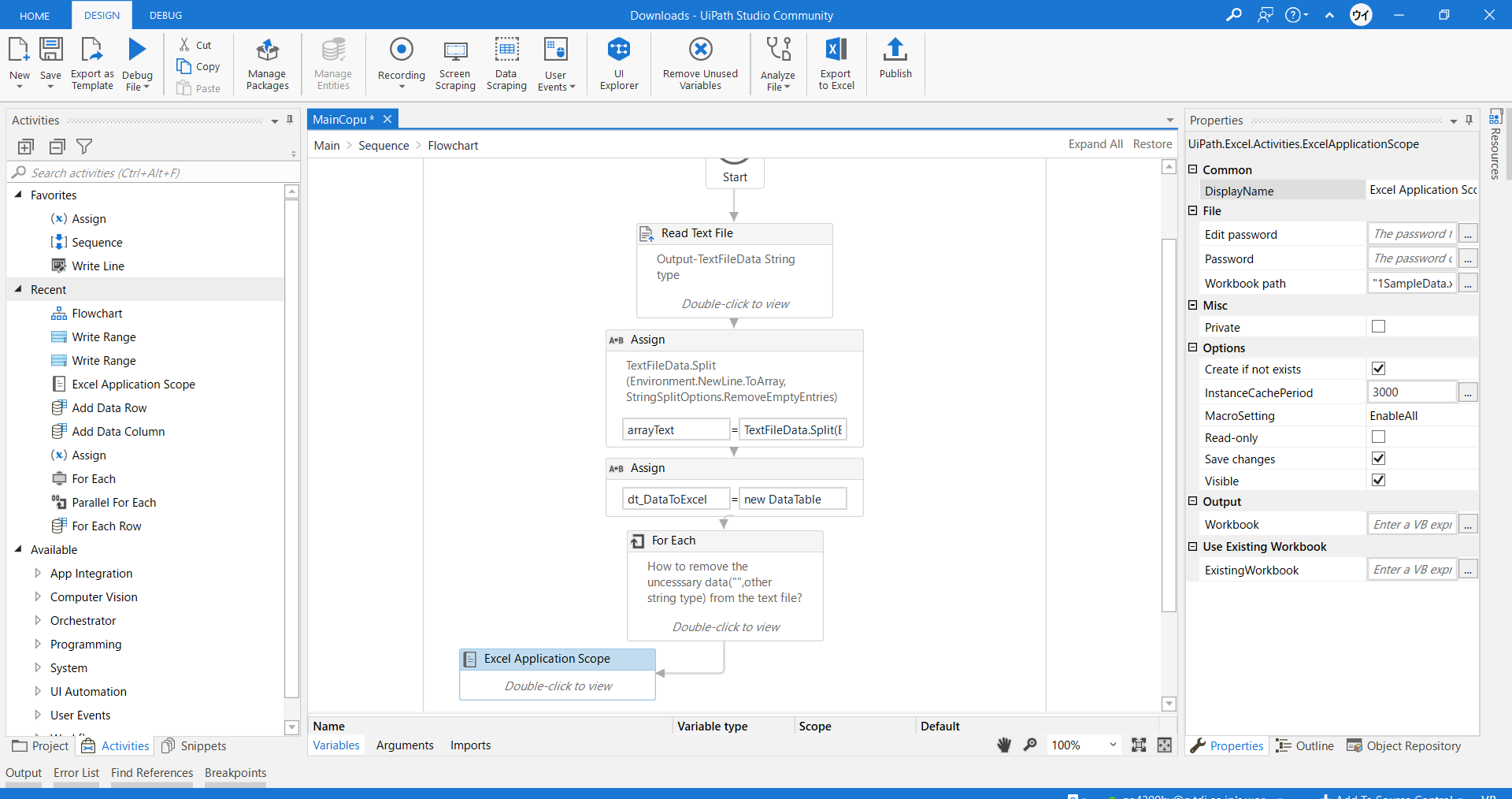
My second question here is,
Actually the original file was PDF. Goal is to get the file in excel format.
which is better changing directly from
PDF EXCL
OR
PDF .txt file Excel
@eimon If you want to Convert a part of data from text file to Excel, if the data is a tabular data then we maybe able to use regular expressions for Splitting the Values and then Converting it to a Datatable and then Write it to an Excel file.
However there are other ways of directly converting from PDF to Excel if it was in that original format, but there may be some additional methods that you would need to apply.
@eimon For the kind of data that you have, will the words “Products List” and “Language Subtitle” be always present. If so, we can take it as start and the end position of the table that you want to extract.
I have kept some considerations in place for the workflow to work accordingly, The Conditions are :
The Table is between the “Products List” and “Language”.
There are only two Columns, and they are separated by a Space.
I have used String manipulations and Regex for getting the desired result. If you want to know more about regex, check the below Topic :
Also, I had noticed that in the original file, for one of the rows, there were no spaces between the date and the first word. Was it by mistake, or was was extracted from the PDF in that way?
Depending on this you may have to consider a different approach or a modification in the approach that I have provided.
@eimon Yes, Mostly regex is used when there are patterns in the data, if you think that your data will always have this specific pattern throughout you can continue on using the regex, but it seems that you have spaces in the First Column as well Or is it always Two Columns that you want to Extract and the Second Column will always have a Date type of value ?
@supermanPunch Thank you Thank you Thank you
1.It is always two columns.
2.First column has space and “/” and “()”
3.Second column is alwasy only date type .
YES … I really appecriate you _ /\ _
@eimon Can you tell me if the first two lines are going to be the same always, or will it differ ? It might be difficult to capture that if it’s varying.
However the subsequent rows can be captured by using groups in regex. Please check and verify the output from the below workflow : Regex Find.zip (2.8 KB)
2.{System.Text.RegularExpressions.Regex.Split(strArray(0),“data”,
RegexOptions.IgnoreCase).FirstOrDefault,“Data”}
How this declaration solve to the requirement of Column 1:AAAAA/ AAAAA Column2: Data
3.When define the columns, What is the meaning of (\d{2}/\d{2}/\d{4})
?
System.Text.RegularExpressions.Regex.Match(item.Trim,“(.*)(\d{2}/\d{2}/\d{4})”).Groups(1).Value
strArray is an array of String variable, Hence it contains a collection of Strings, It is ordered by the index numbers. So the 0th index will have the first Element, 1st index will have the second element and so on… You can use a Message Box Activity to display it’s value. Or you can execute the Workflow in Debug mode and then you’ll be able to see the values in the local Pane.
Since you had confirmed that, Second Column Value Data is always same. I am hardcoding that value in the Add Data row activity, So the remaining value in that row Should be other text values other than the “Data” value. Hence, I am Splitting the text based on the “Data” Value.
It corresponds to the pattern of the Date \d - signifies Digit, {2} - represents the number of occurrences, Hence \d{2} - means 2 occurrences of digits or you can also represent it as \d\d
OK. Setting strArray(0) in message box,the output is AAAAA / AAAA for Column1.
Thanks for hardcoding.
strArray(0) is actually not “data” according to question no1, but the code means whether strArray(0) is “data” or not, ignore the case. Set “data” FirstOrDefault, But the array already has its strArray(0)value , so “data” goes to the second column. AM I right?
Wondering how the “data” appears in the second column.
3.Ok. I tested by putting extra word like 12/08/2020SSS and output 12/08/2020 .I understand it.