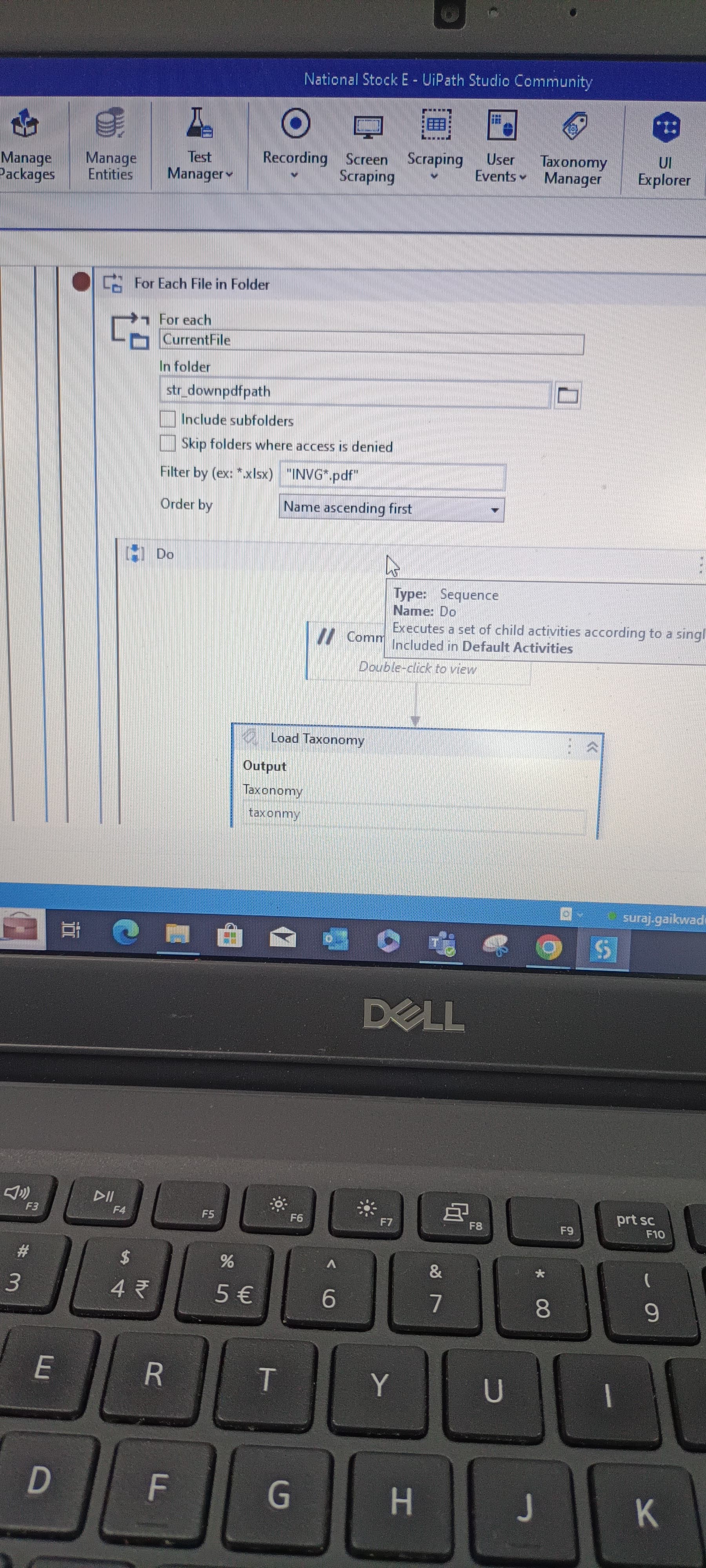
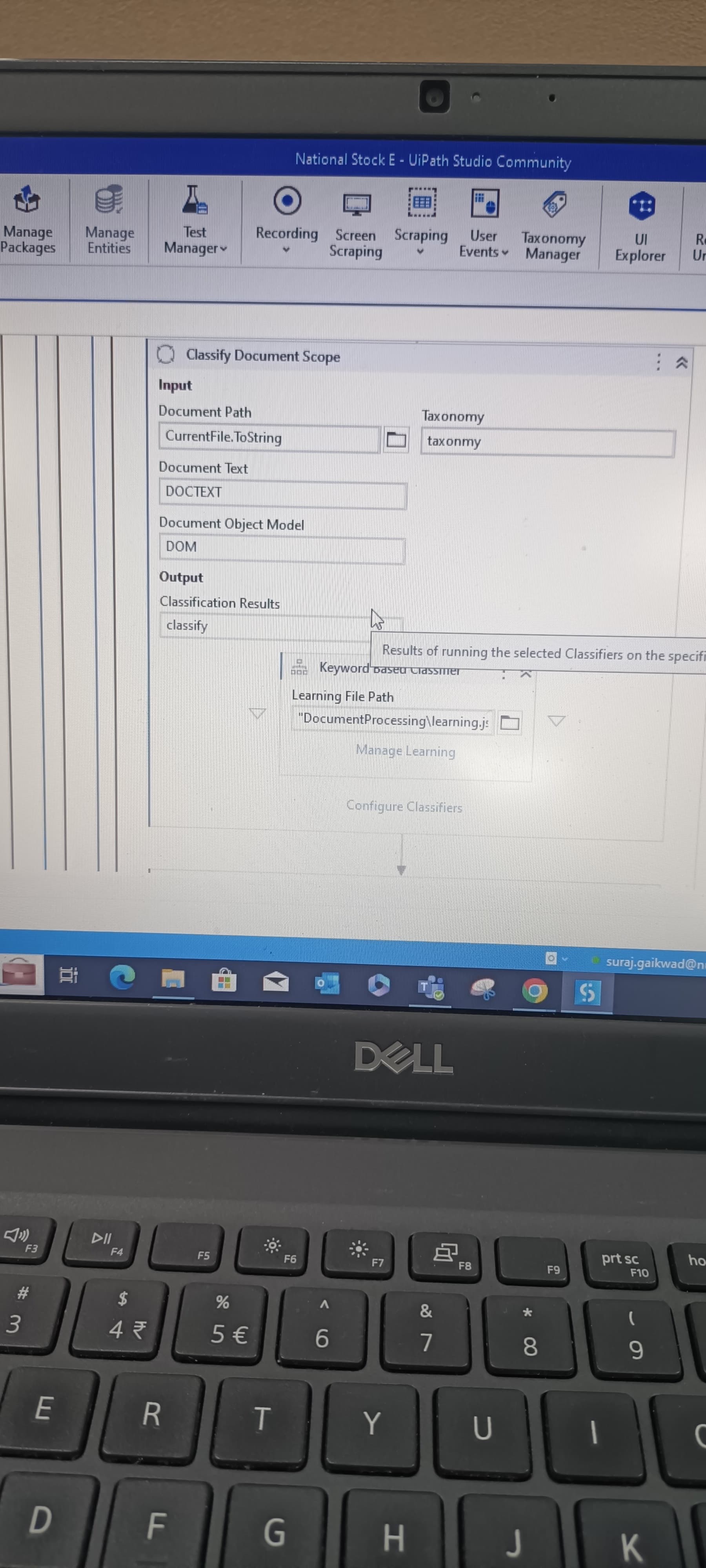
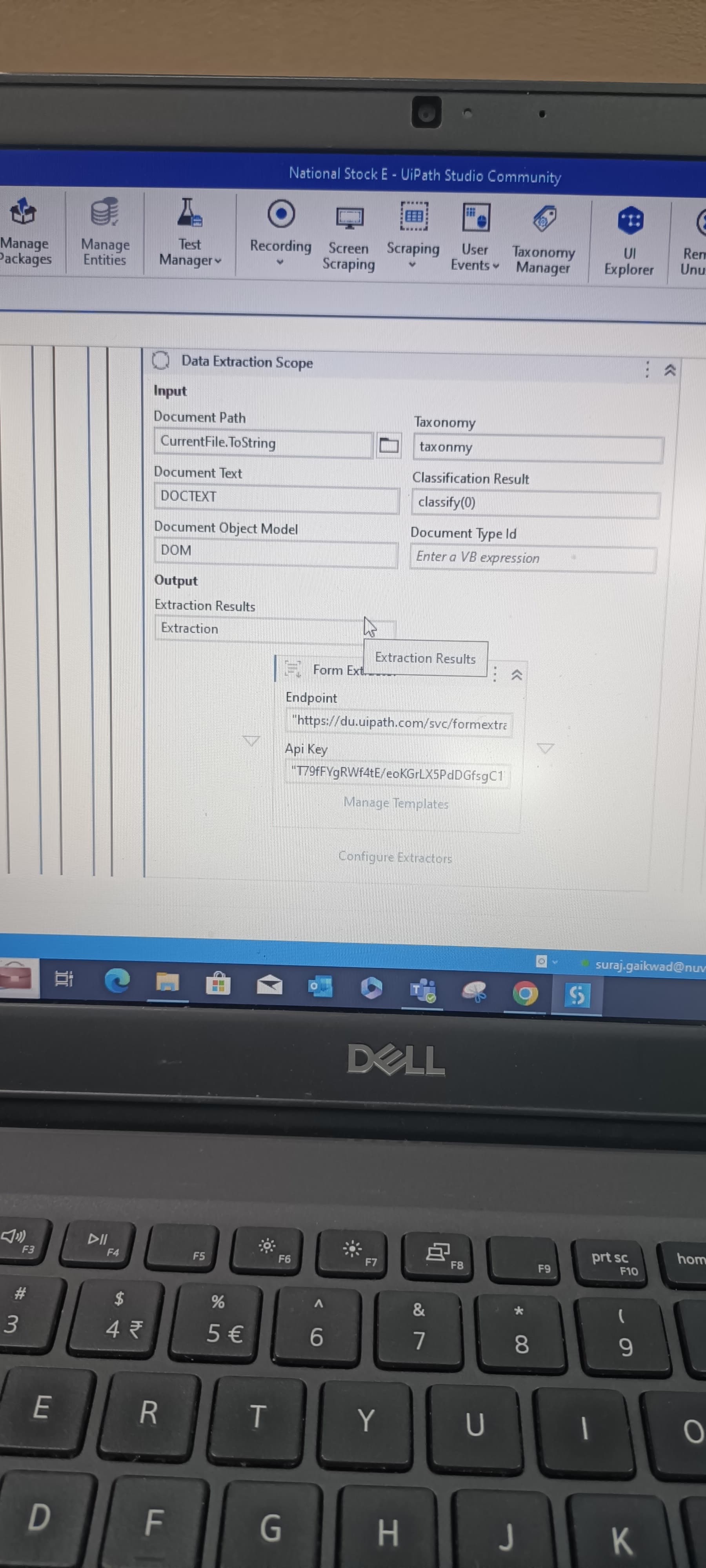
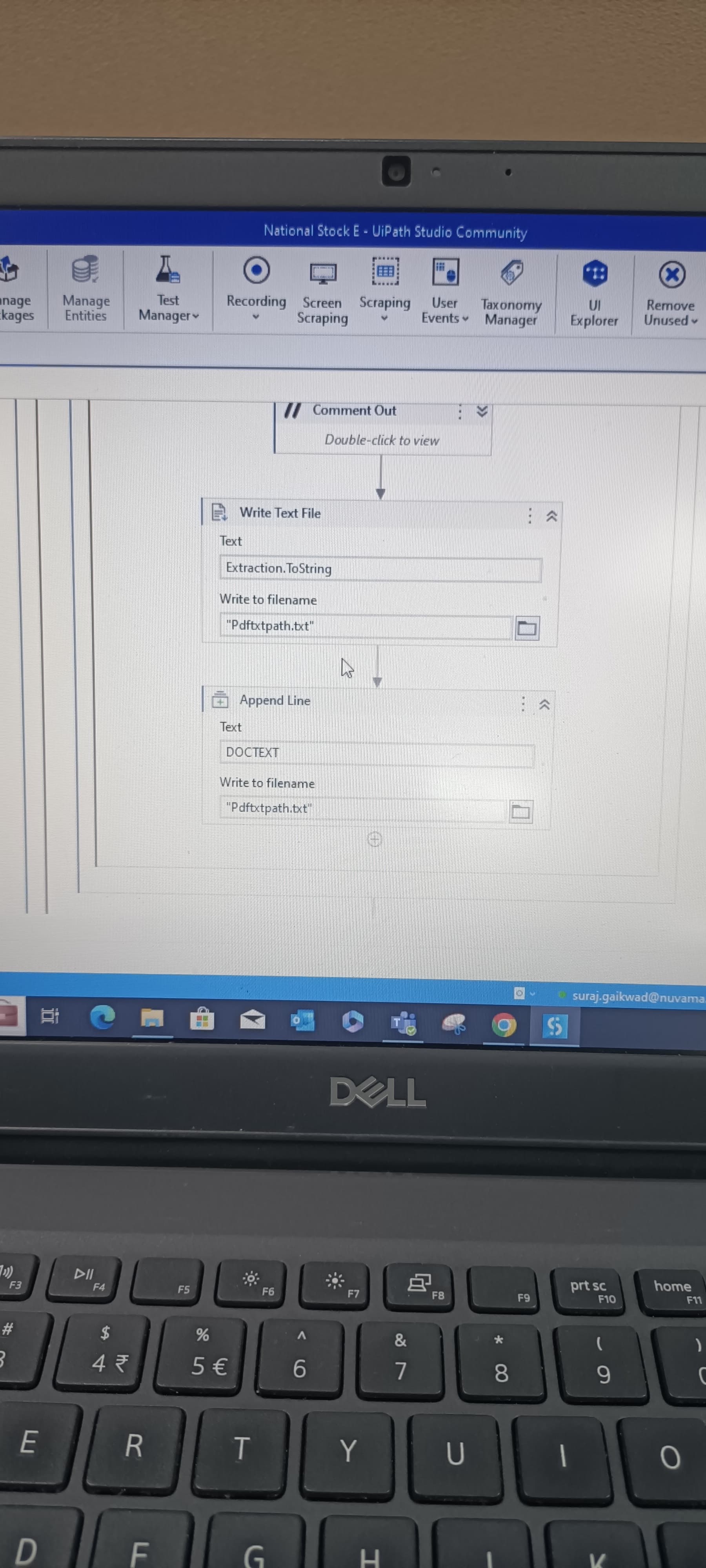
I’m trying to extract text from multiple pdf files but specific text only so i have done till reading all pdf files by using Document understanding so how I do get that text only which I want using Document understanding
These are ss of du and I’m writing pdf text in text file but there is an problem is that first pdf reading it’s write in write text den for second pdf writing and data remove from text file
As the write text file is within the for each loop it creates a new file at each run time so remove the write text file activity from the for each loop and create a file at the start of the program.
You could actually get a DataTable containing the extraction results using the Export Extraction Results activity, then get the header fields and table fields by using DataSet.Tables("Simple Fields") and DataSet.Tables("Line Items")
Hello Suraj,
Got To Data Extraction Scope Activity and click on Configure Extractor. Inside that you would be able to select what field you want to extract and what not.