Download the trained data language file from GitHub - tesseract-ocr/tessdata at 3.04.00
save file “uipath installation directory”/tessdata eg: C:\Program Files (x86)\UiPath Studio\tessdata
restart uipath studio




Try Language “chi_sim” instead of “chi-sim”.
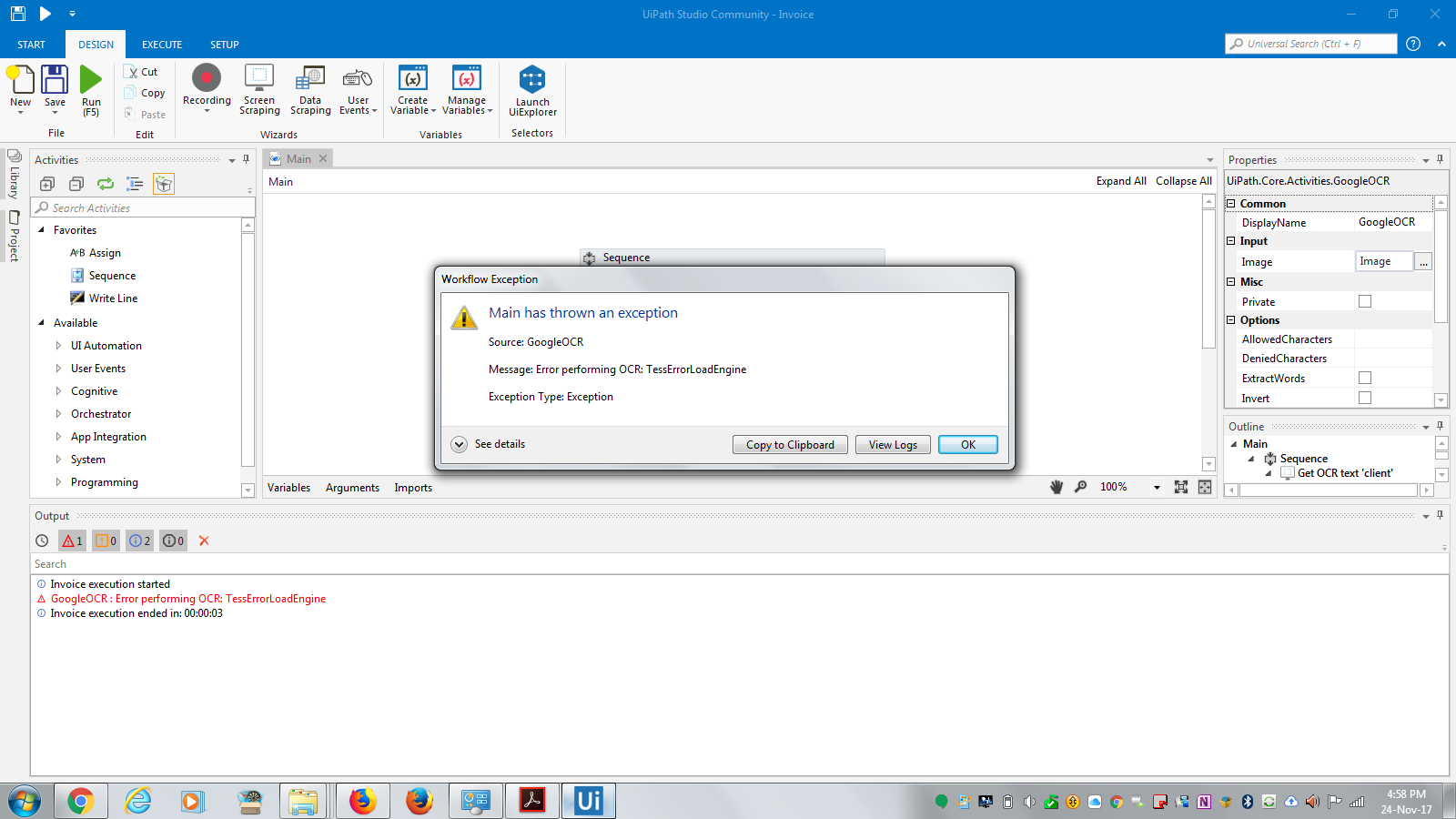
@tamirs, have you tried putting “heb” in the Language property for UiPath.CoreActivities.GoogleOCR? It should go where “rus” is in the screenshot below.

If so, and it didn’t work, make sure your heb.traineddata is in the right folder. Here’s a screenshot of where my tessdata is:

Regards,
burque505
Hey all,
so, this doesn’t seem to apply anymore, as the CE version installs on
C:\Users\<user>\AppData\Local\UiPath.
Within this folder, the only place I found
*.traineddata is
/Activities/UIPath.Vision<whatever version>/build.
Copying the .traineddata to this folder does not make the new language appear.
Any idea what to do?
Cheers
Stratum
Hi,
I saved the file like this: …\AppData\Local\UiPath\app-19.3.0\tessdata\por.traineddata
and it worked!