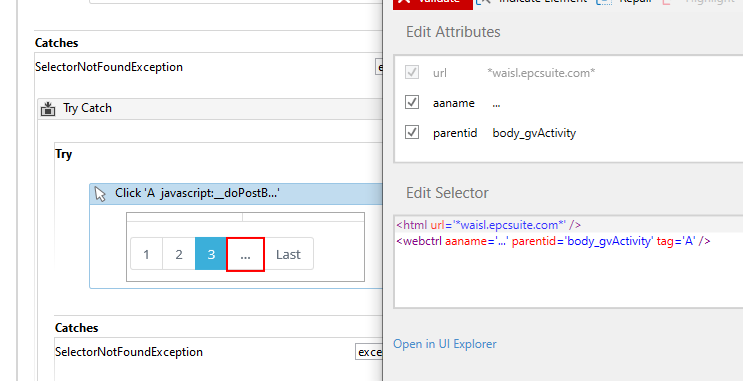
Hi there! I’m trying to extract data from webpages without having next button. if there are more than 3 pages then the website looks like this So I’ve used trycatch. Inside try catch if I got an exception like page 4 not found then catch exception and click on element consisting ‘…’
When i’m applying the same code on pages less than 4 like Then it is reading a non existing element and the data extracted in the 3rd page is also extracting in 4th page.
Same like when i’m applying the workflow on 2 pages it is reading upto 3 pages which not existed.
Please help with your solutions, if you get what i’m trying to ask. Any help would be appreciated.
Could you check if the webpage url changes depending the page you’re on? If it contains the current page number, you could go to last page, get it’s number, and the loop from 1st to last, scraping each one at a time.
 So I’ve used trycatch. Inside try catch if I got an exception like page 4 not found then catch exception and click on element consisting ‘…’
So I’ve used trycatch. Inside try catch if I got an exception like page 4 not found then catch exception and click on element consisting ‘…’ Then it is reading a non existing element and the data extracted in the 3rd page is also extracting in 4th page.
Then it is reading a non existing element and the data extracted in the 3rd page is also extracting in 4th page.