Hi guys. So im trying to learn how the selectors work, so that when I use data scrapping my ui would be more accurate, but I’ve ran into a problem where I dont know what to do. https://allegro.pl/uzytkownik/jgd-parts (THE URL THAT I NEED TO SCRAPPE)
So I need to get the code that is next to the “Numer katalogowy części” text but it is not always in the same place. I try to use Extract table data, because I need to scrappe all the pages (In total 23)
Hi @Gokul_Jayakumar, and thanks for the response, but I’ve already watched theese videos. You see, my main problem is that my data scrapping activity cant find the pattern, because there are 4 almost the same elements there. Im trying to write a selector that would only take the info I need, but im having trouble with that
You can’t get just that one bit of text, because it’s not its own separate object. You get the entire text it’s in - which is probably a SPAN or DIV - and then extract just the part you want using RegEx.
Thanks for the response guys, I appreciate that a lot.
You see guys, im trying to extract it like this: But the main problem is that im getting an error that the elements are almost the same. Is there any way to go around this?
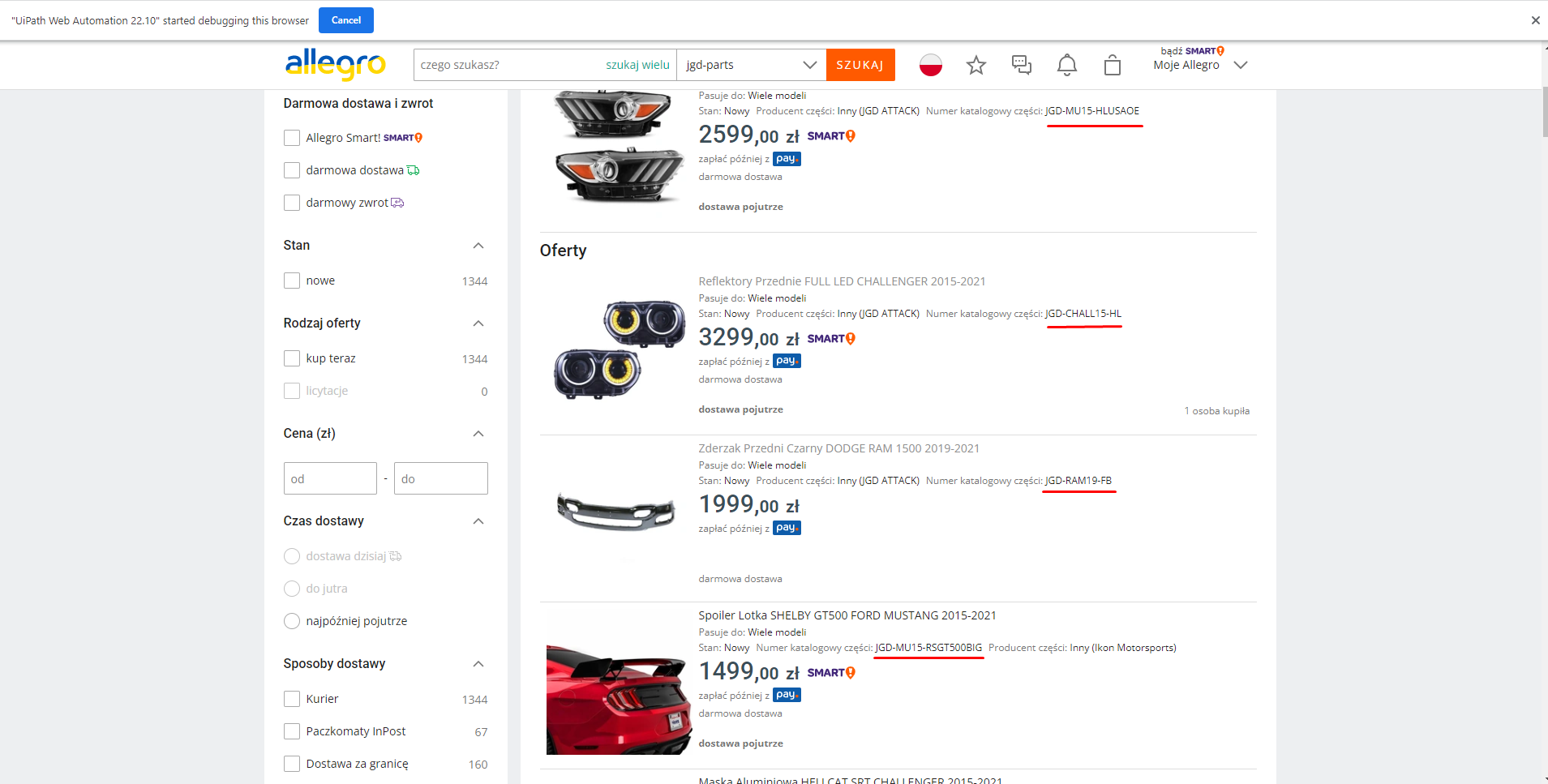
So there is this page that I need to get info from. There are 60 listings per page. I’ve attatched a screenshot of what info I need to scrape for every listing. I have no problem with taking the price for every listing, but the code that is near the sentence “Numer katalogowy części” is complicated for me. It’s not always in the same place. Some listings have it in the end, some in the front or middle. I would love to take the Price, price with arrival, URL of the listing and the code that is near “Numer katalogowy części”, but dont know how.
For now I have it like this:
Yes Gokul, but there is a problem. In the attached screenshot I have an example. The red line is how and what I would love to get from the page. The blue line simbols what the data scrapper takes automatically.
What I mean by that is that the thing I want to get is not always in the same place, thats why I don’t get the info I want. Im trying to figure out is it possible to get the text that is always next to the sentance “Numer katalogowy części”
Yes, but you have the same problem I see. You’r pattern takes the info next to Producent czesci, which I dont need. I only need the text that is next to Numer katalogowy części
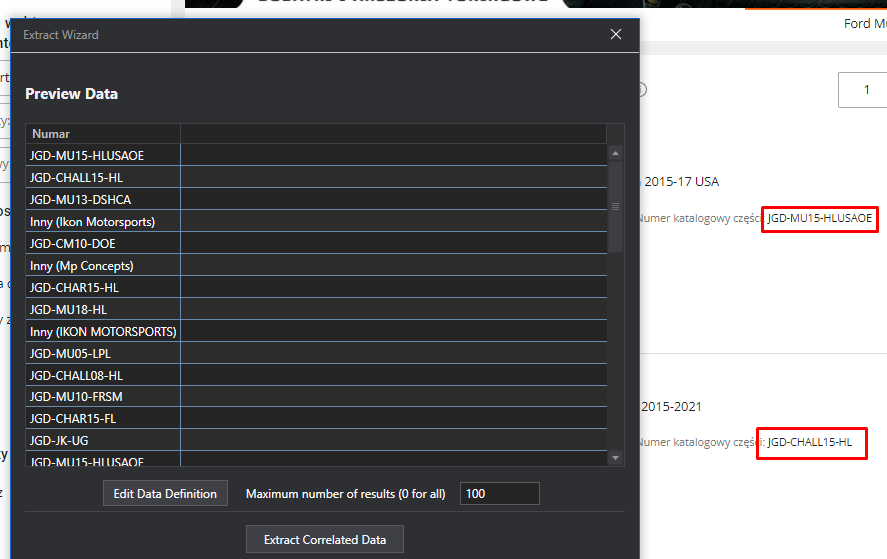
When i did table extraction, I got it like this. It automatically takes the text that is below it, looks for a pattern and only finds this.
Is it possible to just take text that is near the words “Numer katalogowy części”?