Hello guys. I have a situation that I don’t know how to solve. I have a html file where there are 20 rows that need to be scrapped. The rows can be abstracted by the text " {“name” ". But I don’t know how the code should be developed. Any tips? Thanks

the sample is showing JSON data.
in general we would check within an analysis (Browser F12 Webtools / UiExplorer) the holding html element and its attribute. Once this is cleare we use often get Attribute to get the text and then postprocess it like spltitting, JSON Deserializing, JSON Data extraction…
1 Like
Hi @Povilas_Jonikas ,
In UiPath, you can use the Screen Scraping activity to extract data from a web page. This activity will let you specify the details of the data you want to extract, such as the text you mentioned - “{“name”” - and the number of rows you want to extract. You can then use the extracted data to feed into another activity, such as a loop or a data manipulation activity.
Thanks,
1 Like
Thanks guys, I’ll try both of ur suggestions and let you know in a bit! ![]()
Thanks for the tips, but I don’t get it. I can’t find screen scrapping button
Open it in a browser then use Table Extraction wizard.
@Povilas_Jonikas
Thanks for the PM.
Extracting visual driven with options like Extract Table is preferred. Unfortunately a closer look and the structured data confirmed that the structure is not consistent in the flow. So it disturbs the retrieval.
In such cases we can work with find children (not for each uielement, as for each ui element is a derivate of extract datatable) and setup a custom retrieval.
But your idea to use the Script data also have a potential to get it done.
Here some RnD - Prototypes:
Getting the script data:
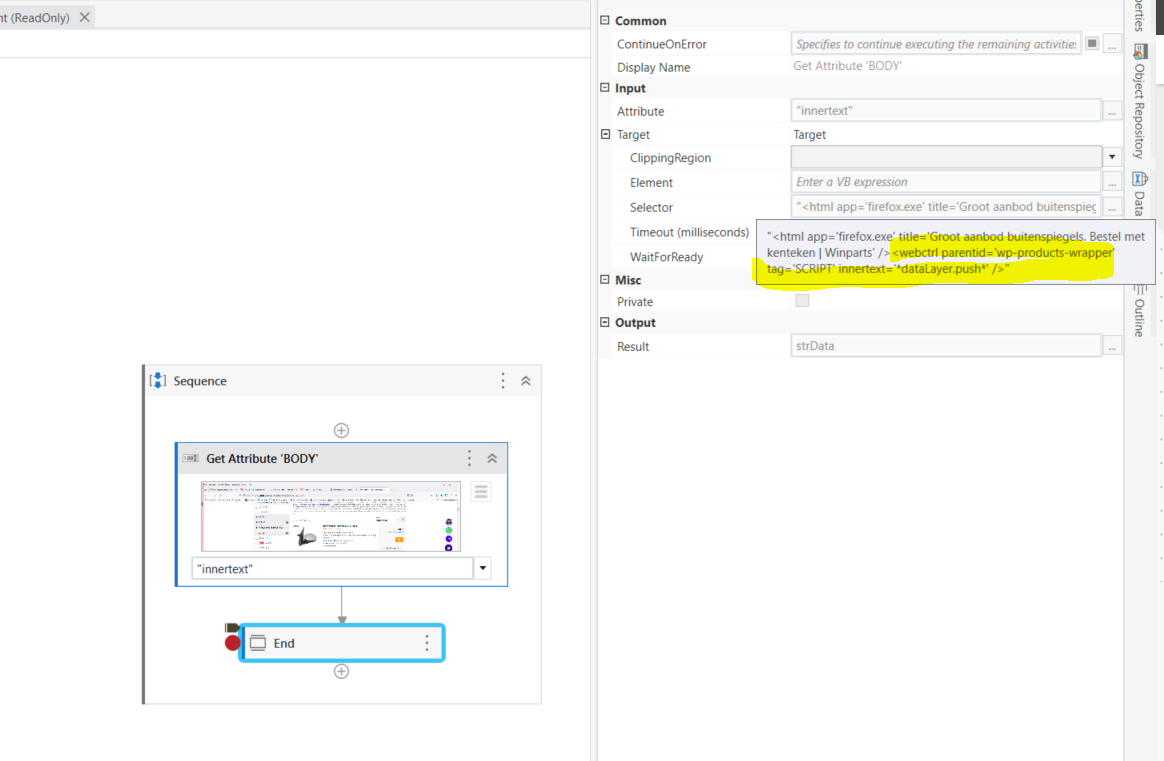

<html app='firefox.exe' title='Groot aanbod buitenspiegels. Bestel met kenteken | Winparts' />
<webctrl parentid='wp-products-wrapper' tag='SCRIPT' innertext='*dataLayer.push*' />
out: strScriptText
Using regex to extract more and retrieve the JArray data:
strData = Regex.Match(strScriptText,"(?<=impressions':)[\s\S]+?\]").Value
Converting it into a datatable:

JArray.Parse(strData).ToObject(Of DataTable)
which is bringing us out the following columns:

Kindly note: we imported the relevant namespaces: System.Text.RegularExpressions | Newtonsoft.Json | Newtonsdoft.Json.Linq
For the paging we would exploit the next button URL pattern containing: ?p=2 , 3,4…
For merging the different extracted page datatable we can use the merge datatable activity
1 Like
Thanks a lot Peter, the guide on how to do this task is really imformative. I will try my best to follow it to succeed.
But i’ll kindly ask for one last thing. Is it possible for you to share the workflow file that you have worked on to make this guide? I can see that my activities layout is different from the one that you have, which is really confusing for me, thanks!
I get an error thrown that webctrl is not declared. How should I declare that variable?
Find some starter help here:
Winparts_nl_byJSONExtraction.xaml (11.4 KB)
Thanks a lot Peter, IT WORKS!
Want to throw a good word in for Peter. I messaged him via PM, he messaged me back as soon as possible. Dug deep to understand my problem and then gave me the solution.
This topic was automatically closed 3 days after the last reply. New replies are no longer allowed.