Hello guys
Im trying to extract data from each column with data scraping but I cant use the data scraping tool because it takes the whole data information even I make the selection for one column only.
I mention the table is a HTML table.
Any idea please?
Hi,
Are you interested in getting only few columns then you could filter the data table.
Yes, I want to take only a few columns from a webtable and I have tried to take the data with datascraping, but the problem is when I try to select only a single cell it tooks the whole data information from the entire row.Any help please?

Here is my table and I want to take the second column with the unique ID and another few columns.I have pressed the no button and the it takes the whole information form the table in the first column.Here how it looks my example
and here is how the data is converted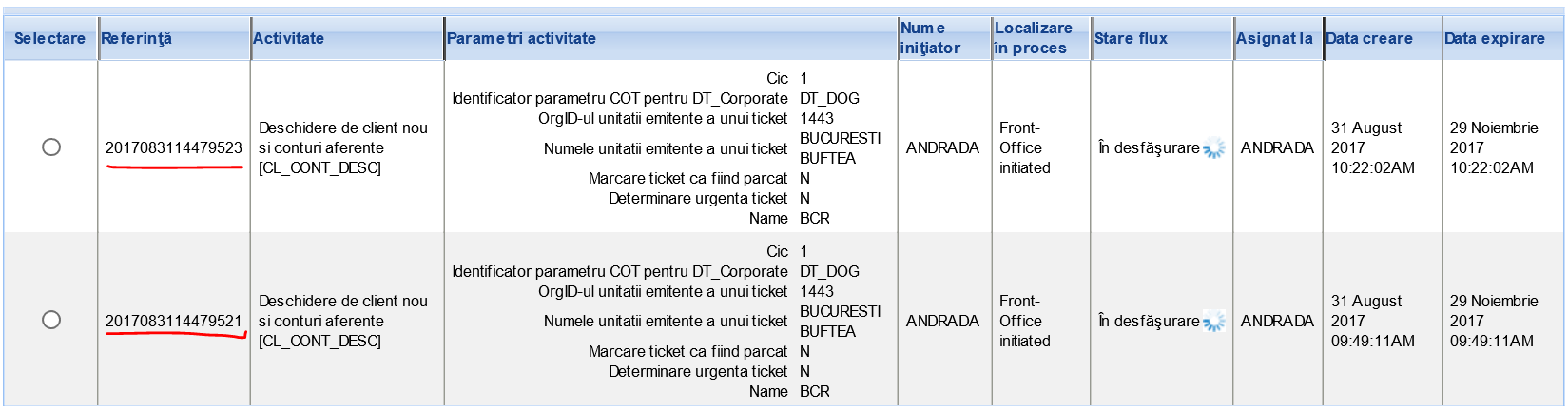

I’m lost some where here.![]()
It is giving you the all the data belong to the column “Parametri activitato”.
That’s what you wanted right.
Or you want the data across row wise?
Hi Victor!
So let’s say you want to extract columns 2, 4, 8, 9.
I think you can extract the whole table, then remove the “unwanted” columns with Remove data column activity based on column name or index. So in the end you’ll be able to write the content of the desired datatable into an Excel file.
Hello, I solved the problem with column build activity and after I made the selection with uipath explorer for each column.After these steps I inserted a flow decision if the elements exists on the page and if exists save the data into excel until it will not find any elements on the page, and it`s works.
Thanks for the help.
2 Likes
Hi All,
Trying to get the filtered extraction in excel sheet, tried adding row and Invoke method as well.
Attaching excel please help to identify the mistake, attaching the xaml
SAP.zip (770.8 KB)
UiPath’s Web Scraping tool can extract almost any type of data from websites and web applications.
Scraping HTML tables is also possible.
You can follow the below steps to scrape tables:
1-Goto Design tab, by clicking the Data Scraping button
2-Select the first and last fields in the web page, document or application that you want to extract data from, so that Studio can deduce the pattern of the information
(Studio automatically detects if you indicated a table cell, and asks you if you want to extract the entire table. If you click Yes, the Extract Wizard displays a preview of the selected table data.)
3-Customize column headers and choose whether or not to extract URLs.
4-Optionally click Extract Correlated Data. This enables you to go through the Extract Wizard again, to extract additional info and add it as a new column in the same table
5-Indicate the Next button in the web page, application or document (if the information you want to extract spans multiple pages).