Hello everyone! For some time now, I have noticed some errors at the start of the robots on the production machines. These are scheduled robots. Currently, we have two production machines, prod-01 and prod-02, with two Robot users, execrpa1 and execrpa2. The error has been that when the robot starts, it uses execrpa01 on machine prod-02.
The machines are connected with their respective users, e.g., execrpa01 on prod-01and execrpa02 on prod-02.
The machine structure and license allocation were already set up this way when I joined the company. I was informed that the orchestrator was designed to distribute executions according to the machine that was free, thus making better use of the production machines. This issue did not exist before, but it has been occurring for some time now. Can you help me understand the reason for this failure, how to solve it, and how to maintain dynamic execution on the available machine?
Run the below command in a powershell.exe console as an Administrator user in the impacted robot VM (this will allow to wait for the session to be created in 10 minutes):
The UiPath_SESSION_TIMEOUT environment variable represent the seconds to wait for a robot user session creation.
If is not defined, default timeout (60 seconds) will be used.
If the above didn’t help, other events on the machine are causing the behavior.
I understand your suggestion, but the error I am receiving is not due to the time for job creation.
When the robot starts on prod 1 with the robot user execrpa01, it starts without any problem. What I understand is happening is that the orchestrator is not identifying which machine is connected with the user execrpa01, meaning it is waiting for an execution with the robot user execrpa01.
Sorry if I wasn’t very clear in my explanation.
Here is an example that worked without any issues.
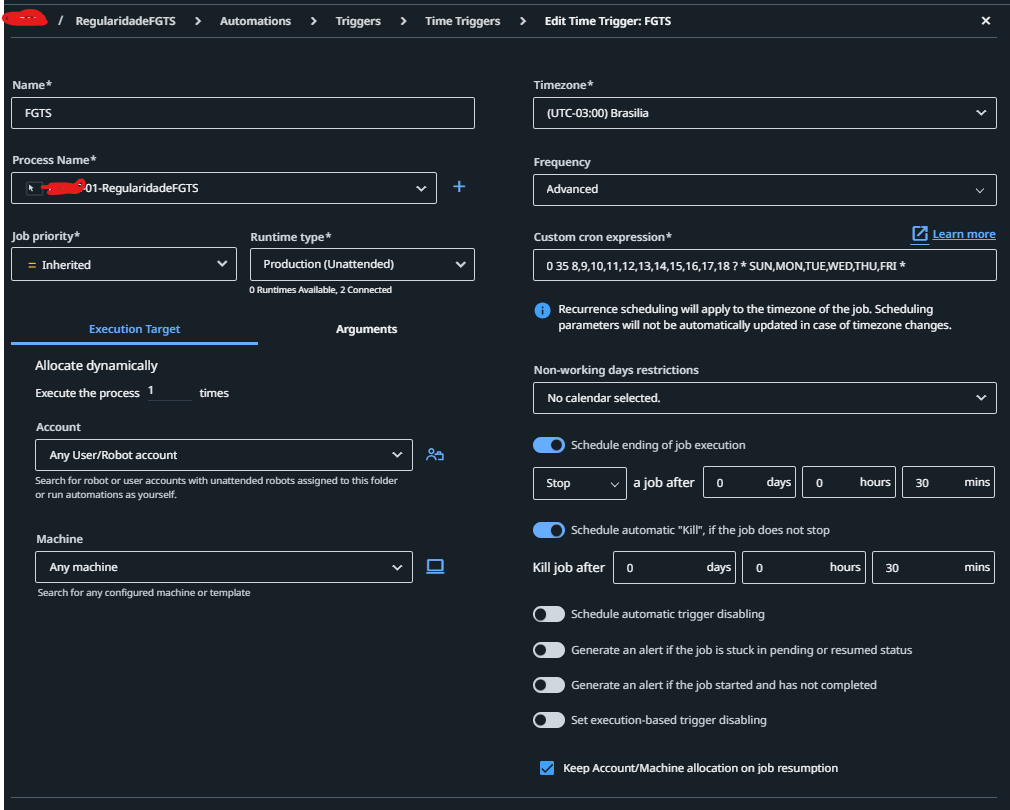
The job will try to run on any available user and any machine that you have added into that Orchestrator folder. Because you are using Dynamic Allocation in your trigger.
If the robot session is busy (because the robots run a job already at that time) and as you are trying to run a foreground session, the job will be tried to run on another machine/robot that may be available.
Also, based on your trigger, you don’t have any unattended licenses left to run the jobs.
This is the issue: why isn’t the orchestrator managing the unavailability of users? For example, if execrpa01 is running a robot, it shouldn’t try to use this robot user anymore. And if both robot users are being used, the orchestrator should leave the job pending.
Note that the robots are configured for the process folder.
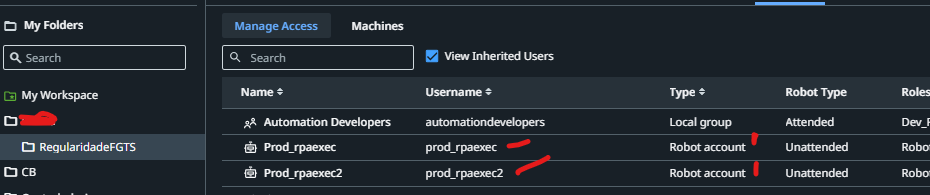
I found the cause of the error and how to fix it. I’m not exactly sure why it only started appearing now, but the issue was having two robot users and two machines.
For example, the error occurred when the orchestrator started a job on the prod01 machine with the robot user rpaexec02, while the machine was already on and logged in with the user rpaexec01.
What I did to resolve it was remove the robot user rpaexec02, leaving only rpaexec01, and I made sure both machines were on and logged in with the user rpaexec01.