I’m trying to extract data from a table in Edge, but I’m not getting all the rows.
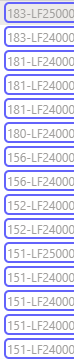
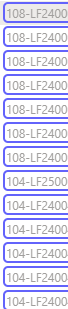
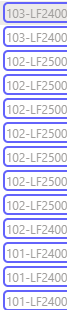
It says the table contains of 28 rows:
But, there’s over 50 (and this is dynamic, could be 100+ tomorrow, could be 10 in 2 days).
As you can see it looks like all of the rows are detected, but it’s not showing up in the datatable/preview. The table is on 1 page and is scrollable, but all data is available (not visible) without scrolling (no lazy loading). So I don’t think scrolling is the problem as there are only 15 rows visible without scrolling, getting 28 rows doesn’t make sense to me.
Have you tried setting the max number of results as 0 and included pagination? UiPath Table Extraction wizard will ask if the results span multiple pages, please select yes and give it a try.
Yes, the maximum number is on 0. It was on 1000 first, didn’t make a difference. I don’t have multiple pages to, for multiple pages I need a ‘next button’, the table is only scrollable. If I select this in UiPath, it doesn’t make a difference either.
Since you are using MS Edge, you can actually use scroll and make this work.
Have your table extraction logic inside a while loop and keep extracting and scrolling until the row count is not equal to the total rows extracted. To give you an overview, here’s how your workflow should look like:
Do While
TotalRows = RowsExtracted
Table Extraction
RowsExtracted = Table.Rows.Count
Scroll
While Condition Check (TotalRows <> RowsExtracted)
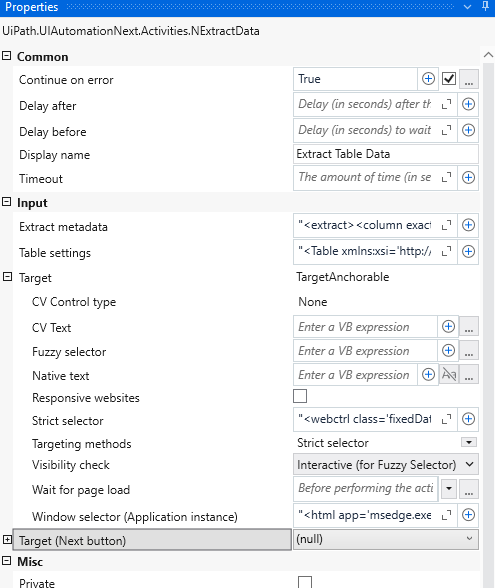
Can you check the properties, there are any customizations happened to extract some range of data,
if possible please share the properties screen shot of Extract table
His solution says: “The problem was appearing because of use-application browser activity browser. As you said table is not in a stable state and it was confusing. I ll pay much more attention for the next times.” Any idea what he means? You need a use application browser activity to scrape the table, right?
Yes, so I don’t understand what his solution was. Not sure how to fix this, but will watch some YT tutorials I guess, maybe it helps. Thanks for trying.
I got a bit further, if I scroll down before extracting I get different rows (the bottom 28 ones). If I let it run without scrolling I get the top 22. So now I need to figure out how to extract data, then scroll down, extract again, but I obviously don’t want duplicate rows. Any idea how to do this in the best possible way?
Then after each extraction, use merge the data table to merge the each data after scrolling, after that use remove duplicate rows activity to remove the duplicate data. Finally you will get output
Since we are looping through the table, you need to continuously merge the extracted DT to a final DT (create the variable and initialize it outside the loop) and then let the loop run. I’d also suggest you remove the fuzzy selector and run it with just the strict selector.
Thanks for this one, this seems to work. Do you know if it would be possible to scroll until it got all data? Because the data in the table changes dynamically, now there’s about 50 rows, but could be 200 tomorrow and 100 in 2 days again. I could just let it scroll 50 or 100 times to be sure it gets all data, but if I could set this to stop when it got all data it would be even better.