I want to extract text from pdf of size 50 pages and there are about 60 of them. I want to extract this text into different excel cells. Can you please help me with how to automate this using UIpath?
@Meet_Shukla - Couple of options
- Read pdf text → then using string manipulation/Regex to extract the text needed
- Document Understanding
Is it just one value? or Multi values from multiple pages??
It’s the entire pdf text for about 50 pages. Can you share with me the proper syntax if you are able to do this.
Sorry your requirement is not clear. Please post some screenshot your pdf(by masking sensitive info) and let us know what field you want to extract ? For your reference:
https://www.youtube.com/results?search_query=extract+data+from+pdf+uipath
Bank of England Inflation Report 13 August 2014.pdf (1.1 MB)
For example, this is the pdf with around 58 pages, let’s say I have 40 more such pdfs. I want to extract the entire text from each pdf i.e from page 1 to page 58. I want to automate this for the rest of the 40 pdfs. Hope you understand now. Let me know if you need anything more by my side to help me with this. thankyou in advance for your help.
Somehow I get it. So you just want to convert all the pages to text and write it to each excel cell Say File 1: 58 page from A1 to A58??
1 cell per pdf so if 40 pdfs then A1:A40 in excel. The entire text of a pdf goes into one cell.
@Meet_Shukla - here you go…This is sample workflow…

-
Build DataTable
-
For each - Type Argument String…
Directory.GetFiles("YourFolderName","*.pdf") -
Read PDF text and Store the output in a string varaible.
-
Add DataRow…Use the string variable from the previous activity in a arrayrow and dt is from build datatable.


My Output → I had 4 pdfs in the folder, so i see output got written into A2:A5

Hope this helps…
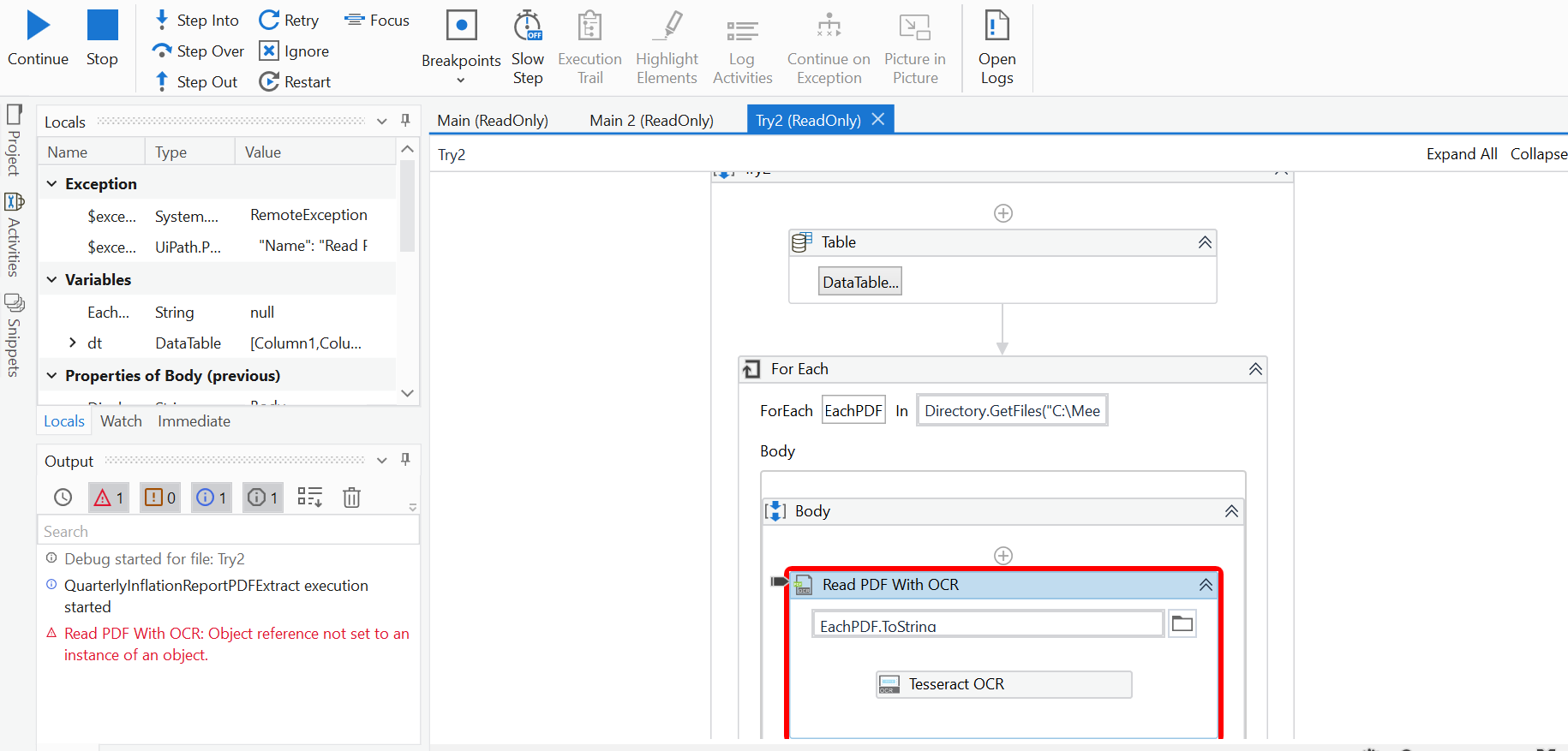
@Meet_Shukla - Share the screenshot properties for Read PDF with OCR , Tessaract OCR and next activity …or share your xaml.
If you For Each Argument type is String…then you don’t have to use EachPDF.tostring…just EachPDF should be good…
Try2.xaml (10.2 KB)
Here it is.
@Meet_Shukla - you did not follow the instructions provided. you should create a output string variable in the “Text” field, in “Tessaract OCR”. and use that variable in the datarow.
I didn’t used {EachPDF} in the add datarow. Please check here…
Try2.xaml (10.1 KB)
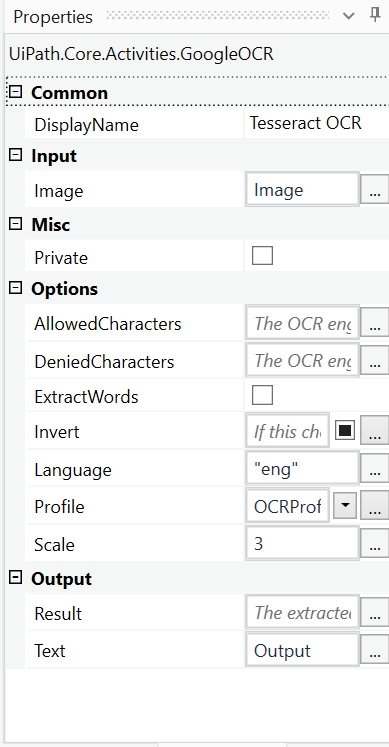

Is it correct now ? With the above arrangements i am still getting the same error. Please Let me know what i did wrong. Thanks
@Meet_Shukla - Here you go…
PDF2Excel.zip (998.2 KB)
Since Tessaract is not running on my end, I have used MS OCR, feel free to change it.
Hope this fixes your issue.
Hey, the code did run but it is not writing anything in excel. I am not able to recognize the issue. I am attaching the XAML, excel, and pdf’s here for your reference if you can determine why is this happening, please let me know. Thanks
PdfToExcel.xlsx (8.5 KB)
Bank of England Inflation Report 13 August 2014.pdf (1.1 MB)
Bank of England Inflation Report 14 May 2014.pdf (767.3 KB)
Try 3 (28th July).xaml (10.0 KB)
This is not how I built and shared the code. Please see how I built my activities and where I put the add data row etc…etc…
I didn’t see Text value in the Tessaract OCR. your Add datarow is outside the For Each…etc…etc…lot of pieces are missing…

Please take pertinent academy courses, that would help you in understanding the flow better and put you in the very good spot.
Hope you understand.
This topic was automatically closed 3 days after the last reply. New replies are no longer allowed.