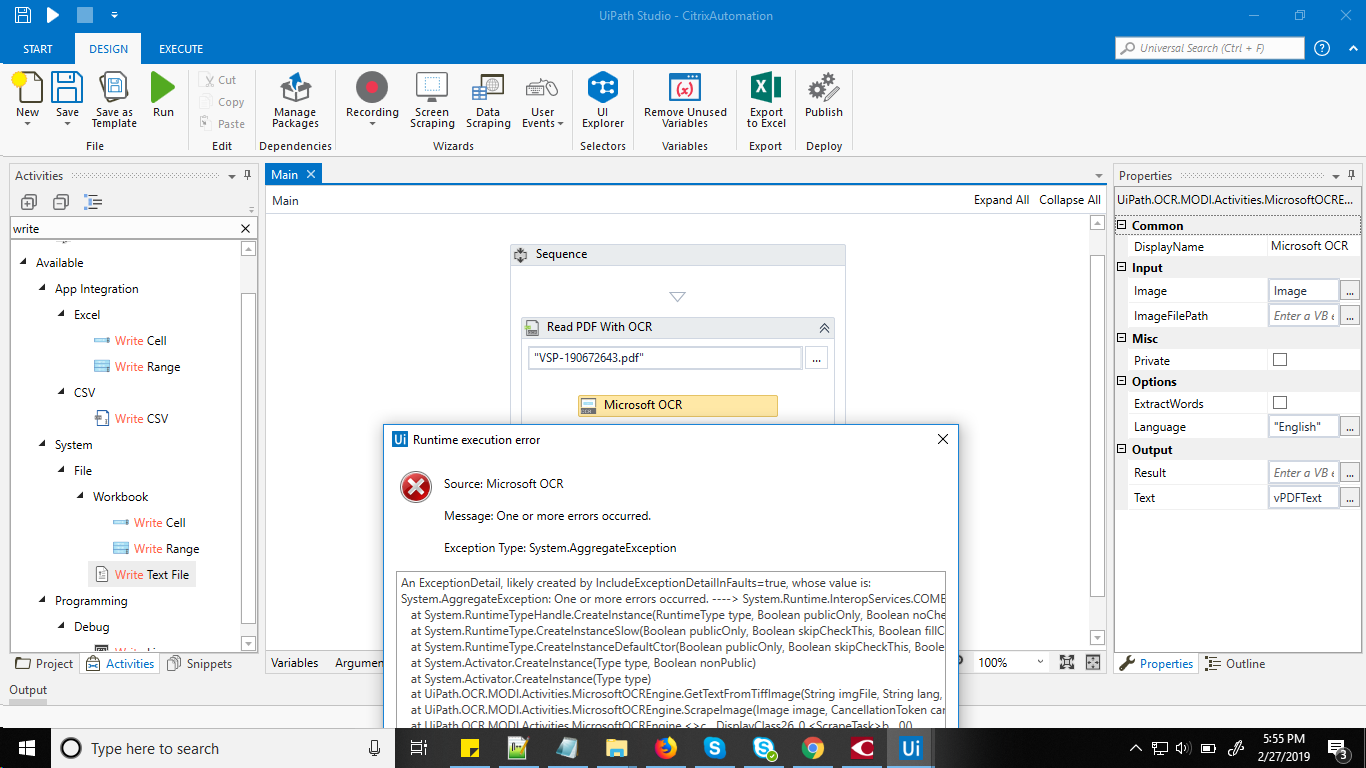
I’m getting this error while using Google OCR in my workflow.
Can you suggest how to overcome this.
Additionally :

Thanks,
Venky.
I’m getting this error while using Google OCR in my workflow.
Can you suggest how to overcome this.
Additionally :
Thanks,
Venky.
Hi,
By looking at the screenshot it looks like your trying to scrape pdf by using screen scraping wizard .
I suggest please use **Read PDF Text (**Native PDF) or Read PDF with OCR(Scanned PDF) activity and drop Microsoft or google OCR for better result inside the container…
reg. second screen shot , Yes- I tried to scrape PDF.
But reg. the first one - I have used “Read PDF with OCR” then dropped Google OCR to read.
Then i got the error.
Is it working fine with “Microsoft OCR Engine”.?
Please attach the workflow.
No, Microsoft OCR is not appearing in activities panel. have updated all packages too, Still i did not get Microsoft OCR.
which version of UiPath your using.
MS OCR comes by default for recent version 2016.2.6274
Please refer.
I’m using UiPath community edition software and I’m getting error stating “System.Exception: Error performing OCR: TessPreprocessError” while using Read PDF with OCR.
Even screen scraping was also giving error when ever I use google OCR though the required package is present in the following location C:\Users\Monster.nuget\packages\uipath.vision\1.2.0\build\tessdata\eng.traineddata
C:\Users\Monster.nuget\packages\uipath.vision\1.1.0\build\tessdata\eng.traineddata

Can you share your PDF file if it is not confidential
And check your PDF package is updated version or not

Best Regards,
Naveen Ch
Hi Naveen,
PFAText and Image PDF.pdf (131.1 KB)
Yes, PDF package is updated version
Hello i have the same error did you find any solution?
Could you try installing this Windows Update: KB2533623.
No, Still the same issue
It is working after installing this Windows Update: KB2533623.
Thank You everyone and specially @houdaui
Hi all,
Faced the similar kind of issue when trying to read the PDF text using Read PDF Text using OCR activity. I have used Microsoft OCR.
Anyone got resolution for this yet? I’m using Windows 10 and UiPath v. 2019.4.3. Thank you!