MOMOMOMO
November 19, 2024, 9:21am
1
IntelligentOCRによるデータ抽出の自動化を実施したいのですが、
Request PredictionId:https://du-jp.uipath.com/cjk-ocr ”)を設定したうえでメッセージボックスに出力した際には正常に動作します。フォーム抽出器でエラーが発生する原因がわかりません。
ご教授いただければと思います。
Yoichi
November 19, 2024, 9:31am
2
こんにちは
どのAPIキーを使用していますでしょうか?
MOMOMOMO
November 19, 2024, 9:44am
3
アクティビティをドロップした際に自動で入力されているAPIキーを使用しています。
また、フォーム抽出器でのエンドポイントの設定を誤っていたので修正(“https://du-jp.uipath.com/svc/formextractor ”)したのですが、下記エラーに躓いてしまいました。
フォーム抽出器
405 Not Allowed
405 Not Allowed
nginx/1.20.1
. CF-RAY: .
Http Response Code: 405
Http Response Content:
405 Not Allowed
405 Not Allowed
nginx/1.20.1
Yoichi
November 19, 2024, 9:48am
4
おそらくEnterprise契約の場合、AI Unit契約が無いとフォーム抽出器は使えないように思えます。
The UiPath Documentation Portal - the home of all our valuable information. Find here everything you need to guide you in your automation journey in the UiPath ecosystem, from complex installation guides to quick tutorials, to practical business...
こちらも参照ください
The UiPath Documentation Portal - the home of all our valuable information. Find here everything you need to guide you in your automation journey in the UiPath ecosystem, from complex installation guides to quick tutorials, to practical business...
1 Like
MOMOMOMO
November 20, 2024, 2:13am
5
AutomationcloudにはDocumentUnderstandingの項目もあるのですが、こちらだけでは使えないのでしょうか?
Yoichi
November 20, 2024, 2:36am
6
上記2つ目のリンクの内容の抜粋が以下になりますので、基本的には使えないものと考えた方が良いと思います。(3rd PartyのOCR等を使えば一部機能は使えるかもしれませんが)
1 Like
MOMOMOMO
November 20, 2024, 9:37am
7
やりたいこととしては請求書等のpdfにあるテキストを読み取ってEXCELに書き出しをしたいのですが、上記の代替案はありますでしょうか。
Yoichi
November 20, 2024, 9:42am
8
まずPDFの中身が画像なのか、テキストが埋め込まれているかでアプローチが変わります。
後者なら以下のアクティビティで、テキスト情報は取得できます。(UiPath.PDF.Activities pacakgeに含まれます)正規表現等の文字列操作だけで取得できそうであれば、こちらだけで完結すると思います。(できるかどうかは内容次第ですね)
The UiPath Documentation Portal - the home of all our valuable information. Find here everything you need to guide you in your automation journey in the UiPath ecosystem, from complex installation guides to quick tutorials, to practical business...
MOMOMOMO
November 20, 2024, 10:48am
9
PDFが画像ベースの場合はOCRでpdfを読み込みを使うほうがよろしいという認識で良いでしょうか。
Yoichi
November 20, 2024, 1:54pm
10
こんにちは
PDFが画像ベースの場合はOCRでpdfを読み込みを使うほうがよろしいという認識で良いでしょうか。
画像ベースの場合、PDFのテキスト読み込みアクティビティは使っても意味がないので、OCRの方を使用します。ただOCRの精度が100%にはならないと思いますので、正規表現での抽出は難しいケースもあると思います。
OCRではない方の読み取りでしょうか?
MOMOMOMO
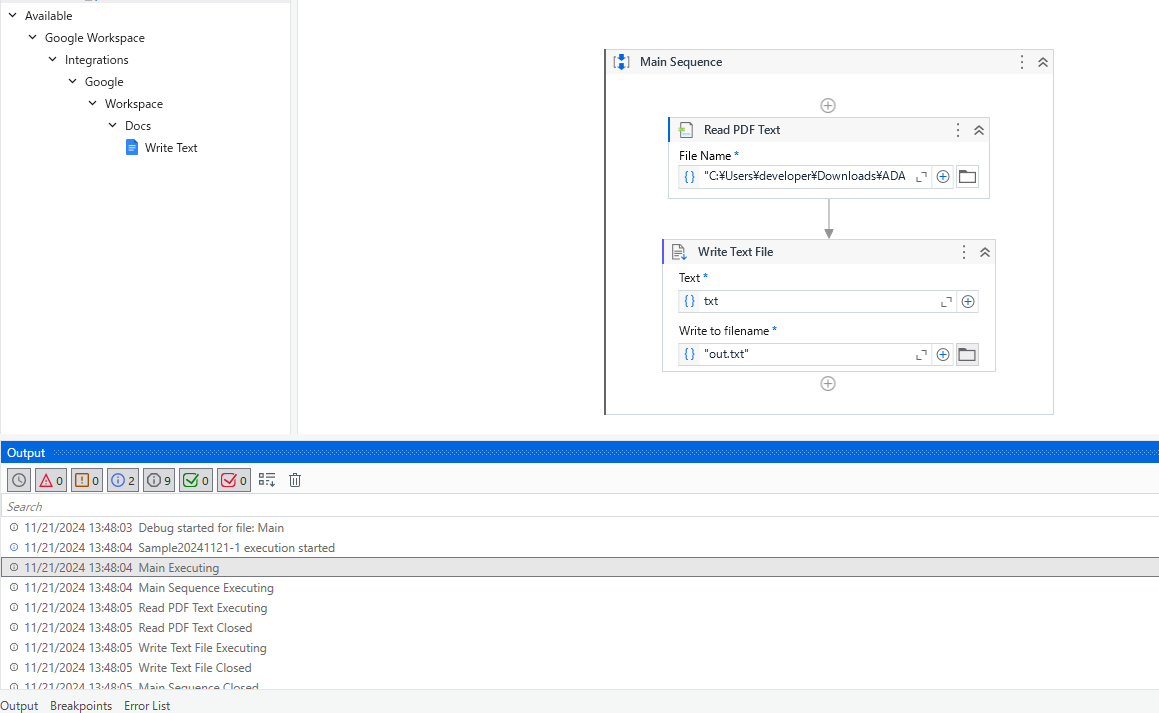
November 21, 2024, 4:44am
11
100KBほどの1枚のpdfですが、1分少しかかっている状況です。
Yoichi
November 21, 2024, 4:51am
12
手元の環境ですと以下URLの資料(1MByte程度)で1秒以下ですね。
ファイル要因か環境要因かを切り分けるために、一度上記試してもらえればと思います。
MOMOMOMO
November 21, 2024, 6:00am
13
テキストへの書き出しは問題ないのですが、Excelへの書き出しだと書き込み先のExcelが開いたまま完了までフリーズしたような形で時間がかかります。
Yoichi
November 21, 2024, 6:02am
14
MOMOMOMO:
Excelへの書き出し
どのようなアクティビティを使って、どのように実装していますでしょうか?
MOMOMOMO
November 22, 2024, 2:23am
15
pdfファイルを読み込み にてpdfを読み込み、出力したテキストを一行ずつExcelに書き込むような実装をしています。
Yoichi
November 22, 2024, 2:48am
16
パフォーマンス重視するなら、一旦テキストに出力して、それを「エクセルファイルを使用」アクティビティで開けば良いように思えます。