I’m trying out the DocumentUnderstanding and DocumentUnderstanding - Invoices ML Skills. I have a trial without GPU, so I think I can only use training on ‘vanilla’ DocumentUnderstanding.
When I try to train them using a training run pipeline (similar to the Ai Fabric training at the academy), the runs fail saying “Training failed for pipeline type: TRAIN_ONLY, error: [Errno 2] No such file or directory: ‘/training/dataset/schema.json’”
As datasets, I’ve used output from previous runs using the ML Extractor. I’m not sure if that’s the right approach.
So where can I check what the right types of input for the datasets are for DocumentUnderstanding? Is the schema.json available anywhere?
I’m running into the same exact problem.
Have you had any luck yet figuring this out? Feels like there should be some sort of documentation available for this somewhere.
I found some documentation for the module, which includes an overview of the file/folder structure necessary for the ML instance to function.
This also mentions the schema.json file, but I don’t yet understand what the file should look like, nor how to properly label my images for the training algorithm.
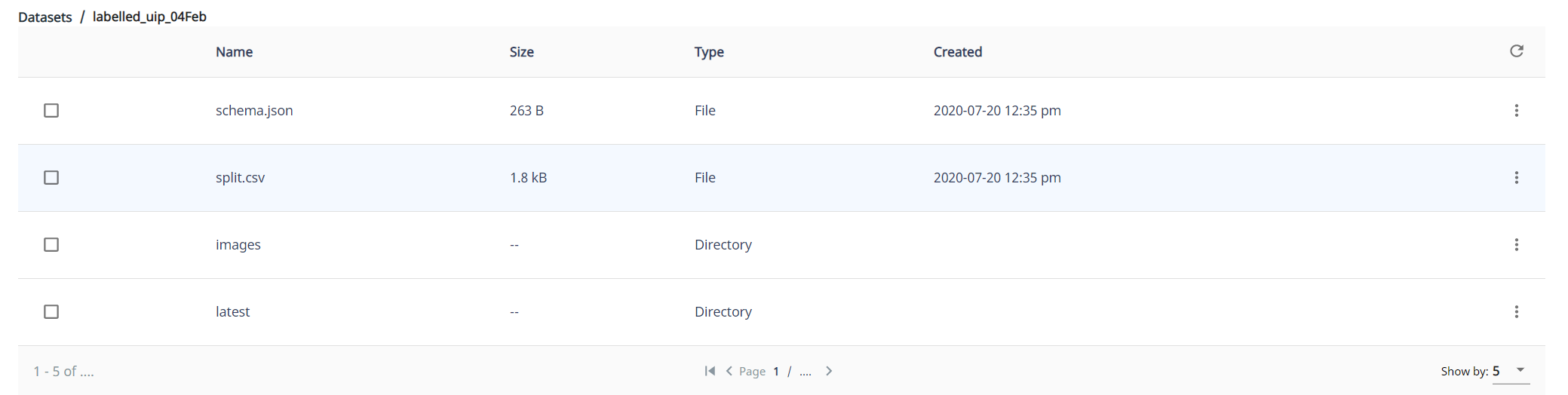
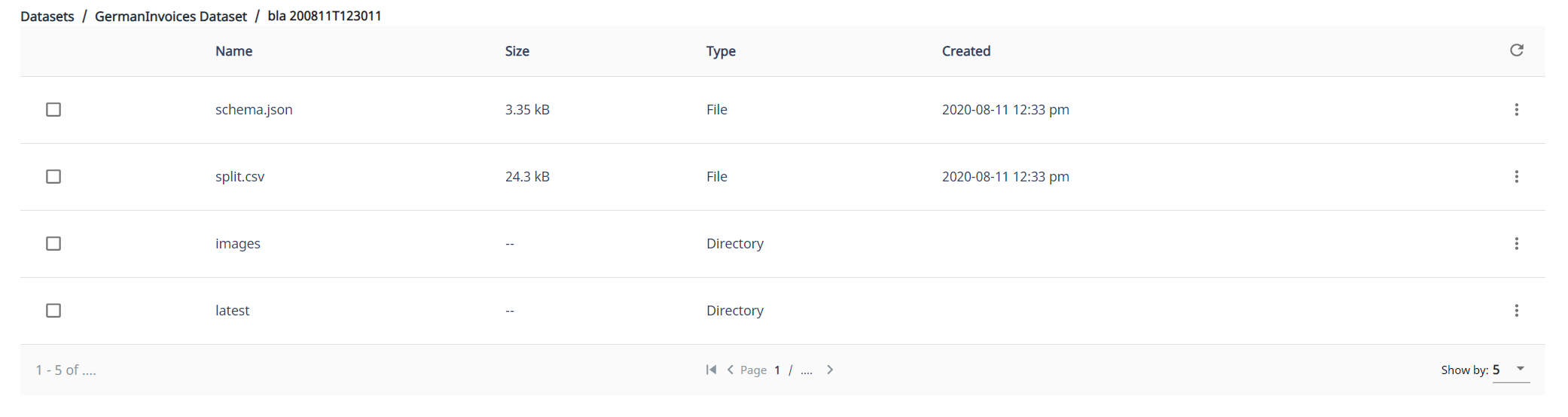
This is common issue which arises when you have one extra folder depth level in your dataset. The dataset you use to train must have 4 things in it: images, latest, schema.json and split.csv. If you try to train on a dataset which has some folder in it, and inside of that folder you have these 4 things, it won’t find them. So a dataset needs to look like this>
I’m personally still unsure how to populate schema.json and the json files within the ‘latest’ folder, though.
How do we format these files to properly indicate/annotate the relevant fields within each training document?
Do you maybe have a sample dataset that could provide more insight into how the data preparation works?
This data is exported by Data Manager, you don’t need to create these files yourself! Data Manager exports a zip file, which you need to unzip and upload the contents to a AIFabric dataset. That zip file contains everything you need.
Aah I see, thanks. I wasn’t aware of Data Managers existence
Unfortunately, I’m experiencing some trouble getting Data Manager to work though.
Didn’t want to stray off this topic’s subject too much, so I created a new topic here.
I’m waiting for credentials for Data Manager, but I’m hoping to avoid it completely because of the complex installation and requirements.
I have the Ai-fabric trial on the cloud platform, which contains: ML Packages > Out of the box Packages > UiPath Document Understanding. I’ll try to put this together with the schema and I suspect this should be a working combination.
(too bad the new Machine Learning Extractor Trainer activty outputs the data different than the model information it uses)