Hello
I am trying to use OCR text exists in order to make sure an employee exists in our database. Employees usually have a unique 5-digit number, but some have a plus-sign followed by 4 number, ex: +1234.
When I use OCR text exists on an employee with a plus-sign, it returns false, even though the employee is in the database. If I output the text from the Google OCR and make a test of my own, it returns True (as it should be).
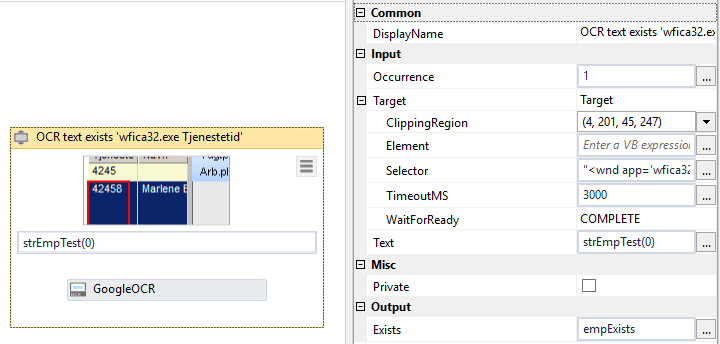
On the informative screenshot you can see a search in the database for an employee with the number 4245, and then the OCR is reading right below this. The search works perfectly with plus-signs and the employee saved in strEmpTest(0) does exists, however the empExists is False.

As mentioned, if I in a message box outputs (strEmpTest(0)=empTest).ToString, then it is a True.
I suppose a workaround would be to use Get OCR Text and make the check myself, but I can not see why there would be a difference, so I am probably making a mistake somewhere ![]()
I am working in Citrix and with an Enterprise Edition of Studio 2018.2.3