I’m trying to OCR the following text:

But, I’m getting the word in two pieces rather than one.
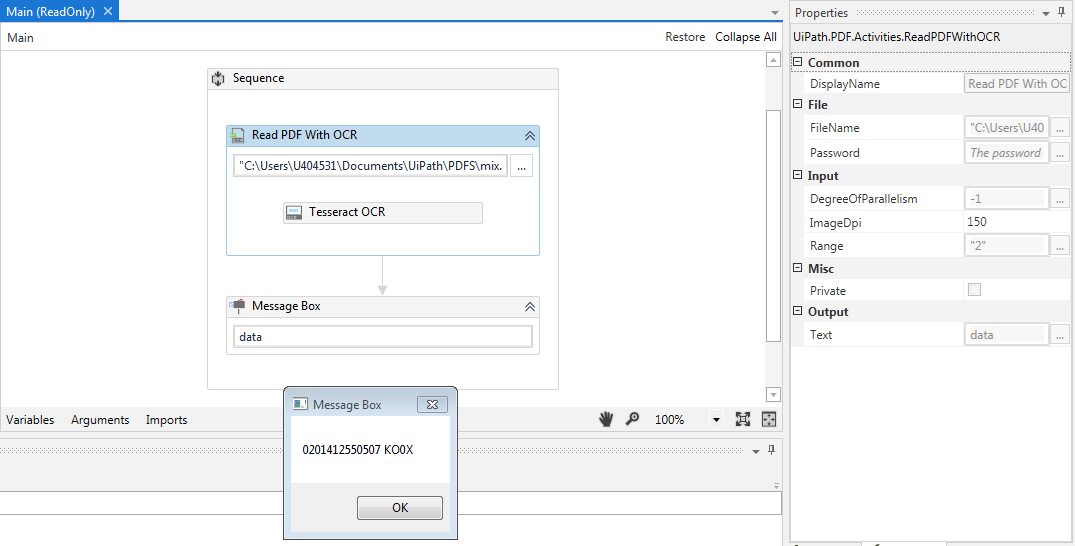
However, when I apply the screen scraper wizard it returns correctly.
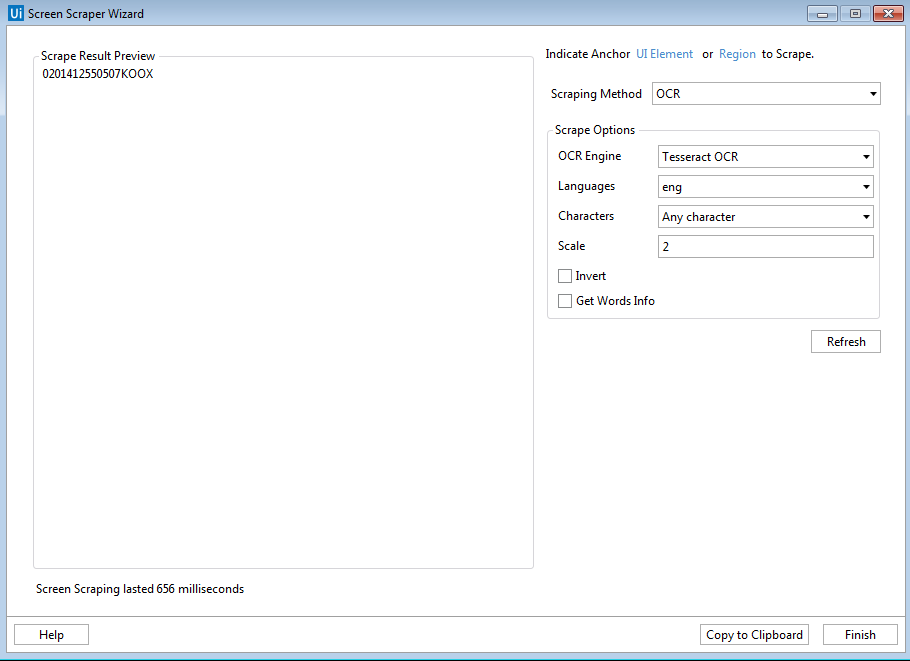
I’m also not trying to use the read text activity, I need to do it with the OCR activity.