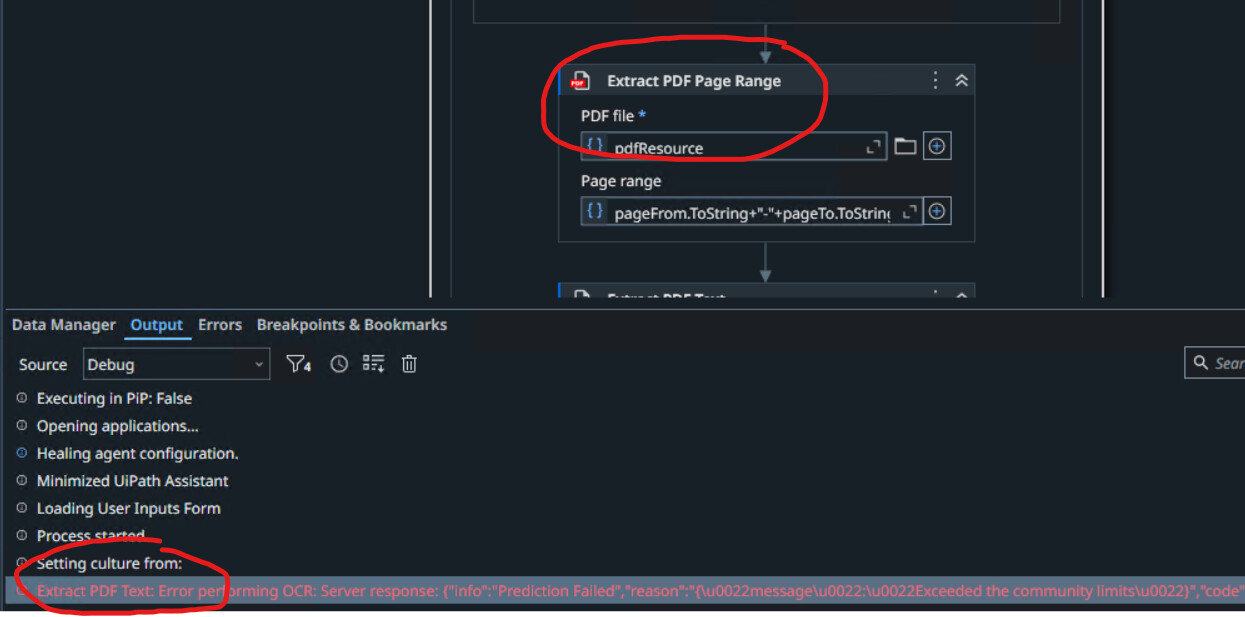
I got shocked this afternoon … I am testing the solution and, after some whole-runs I got:
Extract PDF Text: Error performing OCR: Server response:
{
"info":"Prediction Failed",
"reason":"{\u0022message\u0022:\u0022Exceeded the community limits\u0022}",
"code":"[CommunityLimitExceeded]",
"message":"Exceeded the community limits",
"severity":"Error","parameters":[]
}
Error:UiPathOCRErrorInvalidResponse CF-RAY: ...
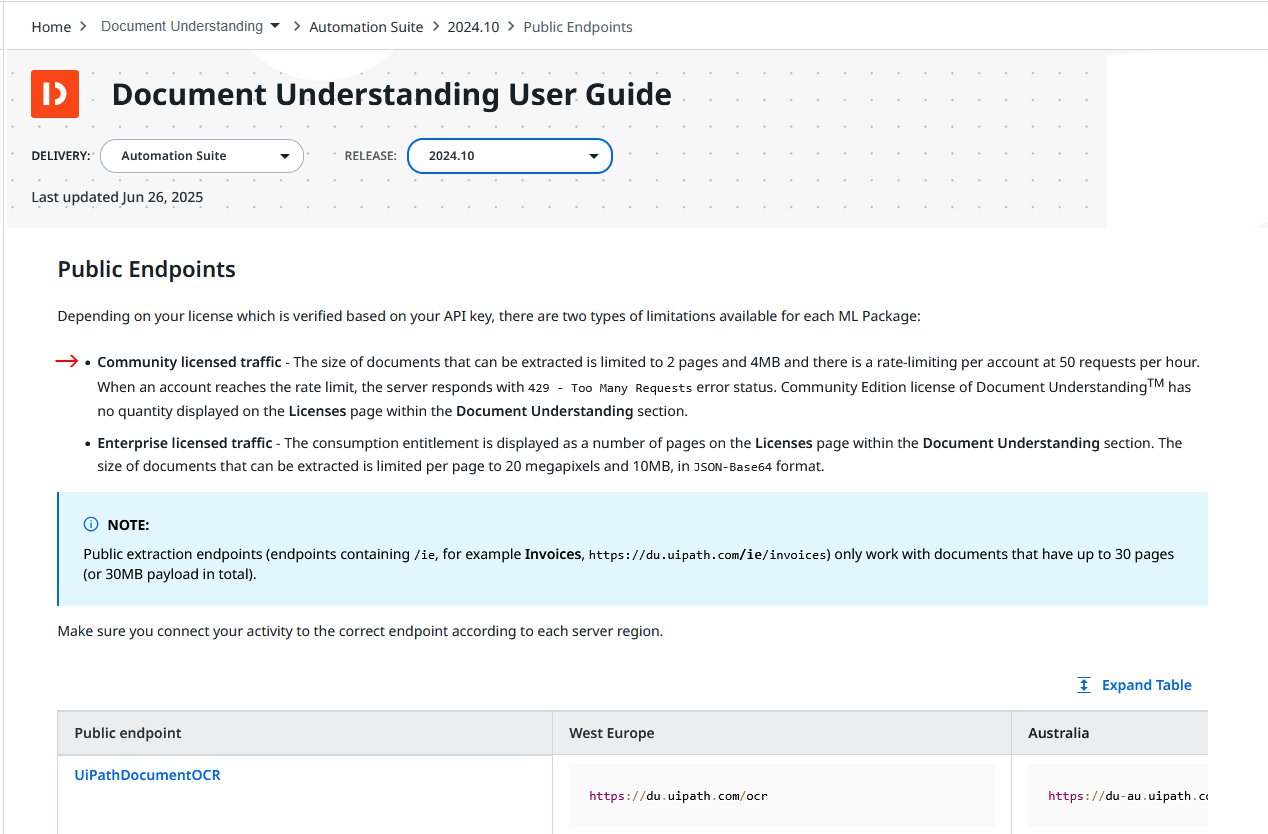
I’m trying to find the info regarding LIMIT RATES HERE: …“API requests made to the server are limited to 30 megapixels per minute for Community licenses”
Since I got the error I have wait more than an hour abd still, I cannot even extract OCR from a single page
I guess then, there is a daily rate limit… Could you guys please tell us which one is it?
Which OCR do you use? If UiPath.Document.OCR, we cannot use it in AutomationCloud under Community plan.
If you just need to get text from PDF using OCR, can you try ReadPDFOCR activity in UiPath.PDF.Activities package? We can use any OCR engine including Local.
It’s very interesting what you’re proposing!, I’m going to try it out and let you know
BTW, the activity package is UiPath.PDF.Activities that follows, theoretically , the rate I’ve shared of 30 megapixels per minute for Community licenses.
That’s the point also, we only have that rate, and it seems that’s not the case (or we have another rate we are not informed about)
I’ve found the Adobe Services Activities in Integration Service ( Activities - About the Adobe PDF Services activities )
Docs are not so good, It doesn’t explain how to use some parts and/or variables. I’m not going into details because I found another solution but it is interesting to take a look.
From the Free Subscription you can perform 500 document operations/month, which is good for small processes.
Solution B
As said in the first post, we have the PDF.Activities package, and its documentation that gives you some limits but not in a clear way (prooved they have not 30MP/h, nor 2 pages/50 requests/hour). We also have lots of different places talking about it but not giving a clear answer. This docs should be revewed as well:
These are not explicitly but the have some figures. We only know PDF Activities is from Document Understanding Activities, nothing else specified.
Solution C
If you don’t need OCR so, you have a pdf coming from a word file for instance, you could read the pdf with Microsoft.Office.Interop.Word Namespace with an Invoke Code (I have done that). It’s a pitty there is not an activity to do so, we are always looking on OCR where there are a lot of cases we don’t need GPU.
Conclusion
So, I would recomment to, first, try to get the data inside your PDF with Word.Interop, then, if you have 0 Chars or less than a reasonable number (I’m thinking in something like, *page-total-count *100Chars minimum per page), it is an scanned document, so you use OCR. Then,I recommend you a mix of PDF.Activities and PDF Services Activities, by catching quota exceptions.
By this way, even if the quotas are changing you will be able to still manage and decide wich quota you want to upgrade depending on the prices.
I’m going to push for docs update and dig a bit more, I’ll bring some info here to help future users.