Hi All,
I have already created batches earlier, can we add new documents to existing batch in document manager or for every import I need to create new batch?
Thanks in Advance!!
Hi All,
I have already created batches earlier, can we add new documents to existing batch in document manager or for every import I need to create new batch?
Thanks in Advance!!
No need to create a new batch to import documents.
You can upload the documents to existing batches. When click on import give the existing batch name and add files then it will added to existing batches.
Hope it helps!!
thanks will try that and lets say I have 2 vendors each has their own invoices, earlier I had created one batch and added docs of 1 vendor its working fine in extraction now my requirement is to add other vendors docs so for that I have created new batch and added the the other vendors document and run the pipeline by selecting new batch which I have created and trained the ML model but now in data extraction its not extracting first vendors data properly, it extracting only second vendors data for which I had created the batch can you pls help to check what I’m missing here
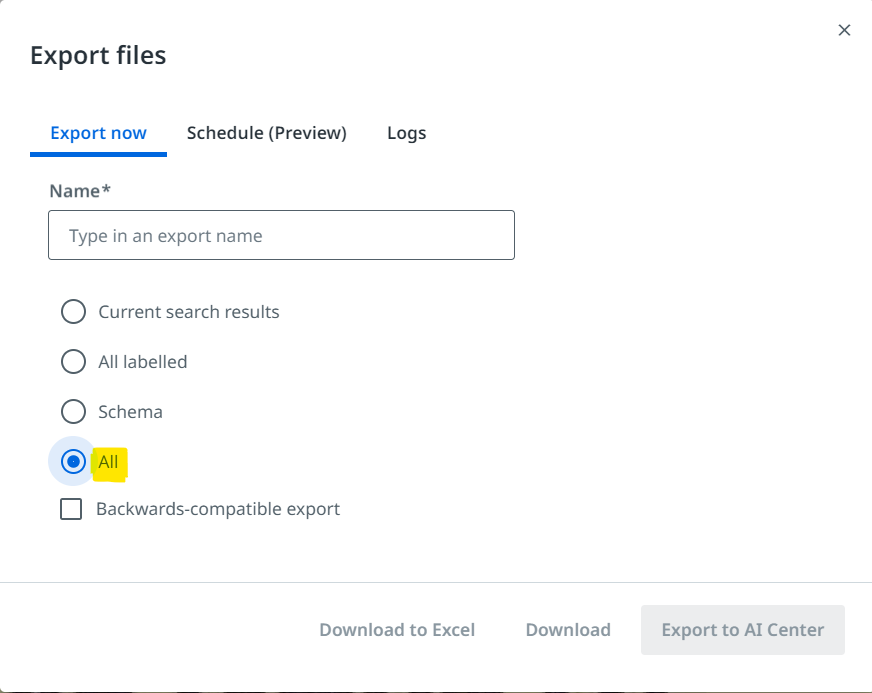
When you are exporting after the labelling of second batch means 2nd vendor. Select the All option as shown in the below image.
While creating the pipeline select the dataset that created in recent.
Hope you understand!!
ok while exporting I was selected All labelled that why it was not extracting data of first vendor is it?
Might be, but not sure, When I will do exporting it I’ll select All option. I am getting the data for the existing batch files also.
I hope you find the solution for your query, Make my post Mark as solution to close the loop… @Parmar_Snehal_Cognizant
Happy Automation!!
I tried selecting All while exporting but still its not extracting few fields, is it while creating the pipeline instead of selecting the dataset that created in recent, I’ll have to select the entire export folder I mean dataset folder?
Train few more documents for vendor1 and vendor2 then do the same and run pipeline. Then check it was extracting or not.
Extracting issues will come when the more files are not trained.
Hope you understand!!
I tried that almost 30 doc I have added and labelled for first vendor but still few fields are missing while extracting data for first vendor but for second its working properly same fields only issue with first
How many files you have given for evaluation set… @Parmar_Snehal_Cognizant
it is extracting data properly for first vendor only if I set the confidence % low
evaluation set I have not added but training set has 53 docs and training & validation set has 66 doc and 56 are labelled and 10 is unlabelled
Where did you set the confidence percentage? Also are you running the train pipeline or full pipeline? Also check if the quality of the Vendor1 document is good same as Vendor 2?