Date extracted in a different format
Expected Date - Effective Date: Apr 16, 2022
Output - Effective Date: A{{p$rE1ff6D, 2at0e22
Please help me with the solution
Date extracted in a different format
Expected Date - Effective Date: Apr 16, 2022
Output - Effective Date: A{{p$rE1ff6D, 2at0e22
Please help me with the solution
Hi @Aman_Jee_US ,
This happens because of improper digitization.
Which OCR are you using?
Thanks,
Nishant
Hello Aman,
need more information on this to give you a targeted answer.
This looks like either an extraction or digitization error.
Thanks for the response. I tried UiPath OCR, Tesseract OCR and Omni Page as well
Thanks @sharon.palawandram ,
What’s the OCR you use in the Machine learning extractor? Is it uipath OCR?
and is it the same result in all the OCRs?
You may want to check your training data. When you label the date in document manager how does the date come? does it come as Apr 16, 2022 or A{{p$rE1ff6D, 2at0e22?
Yes, I am using UiPath OCR and all other OCRs are giving the same result. In the document manager it comes as Apr 16, 2022. I also tried Intelligent & Form Extractor and in Template manager it comes as A{{p$rE1ff6D, 2at0e22. Also in text only view the data has same A{{p$rE1ff6D, 2at0e22
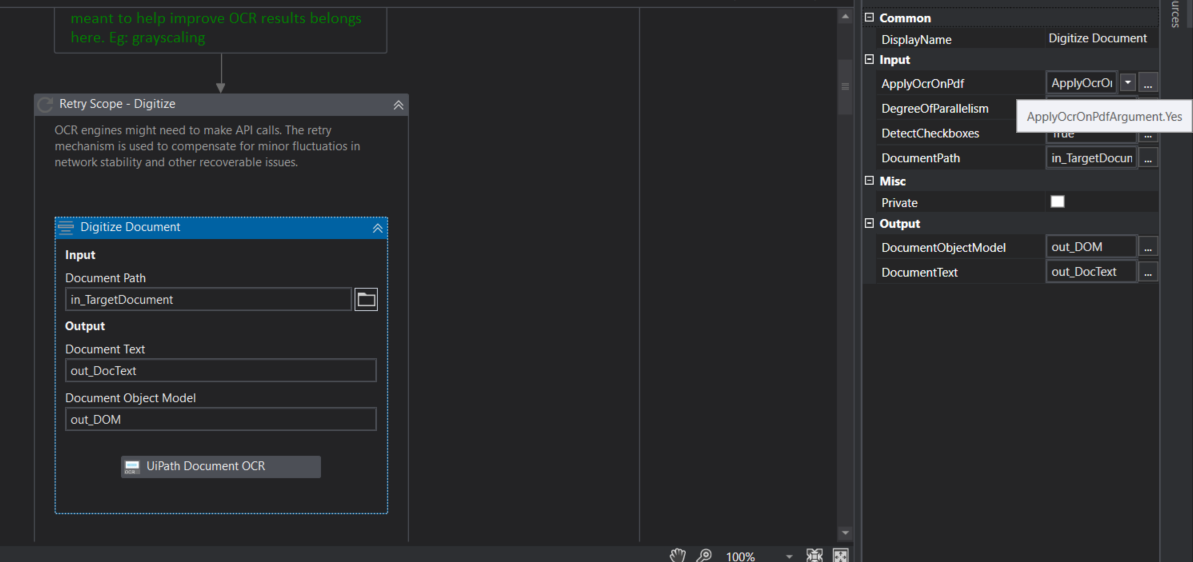
okay. Can you use UiPath Document OCR for this use case and check if the settings in your digitize activity are set to the following?
In your digitize activity, under ApplyOcrOnPDF, set it to “Yes” as shown in the below picture.
and then write your digitized output into a text using the following :
then check DOM_worked.json file and check if your DOM has the correct date or the wrong date.
There’s no way that all OCRs give the same error. There should be something missing apart from changing OCR and Extraction.
In extraction, can you check if you have properly set your ML skill? Have you set it to auto update?
You can also kick off an evaluation pipeline and check if you’re getting the date accurately.