![]() We’re thrilled to announce June is coming with many awesome features, all extremely valuable and long awaited!
We’re thrilled to announce June is coming with many awesome features, all extremely valuable and long awaited! ![]()
 Page Reordering in Classification Station
Page Reordering in Classification Station
Yes, we know, long overdue… but finally here! ![]()
The page reordering feature allows users, during classification validation, to correct any out-of-order pages, so that the DU process downstream (extraction, extraction validation) will execute on the correct order of pages.
All you need to do is update your IntelligentOCR.Activities pack to 6.25.0-preview or higher, go to the Create Document Classification Action or Present Classification Station activity, and set the EnablePageReordering input argument to True.
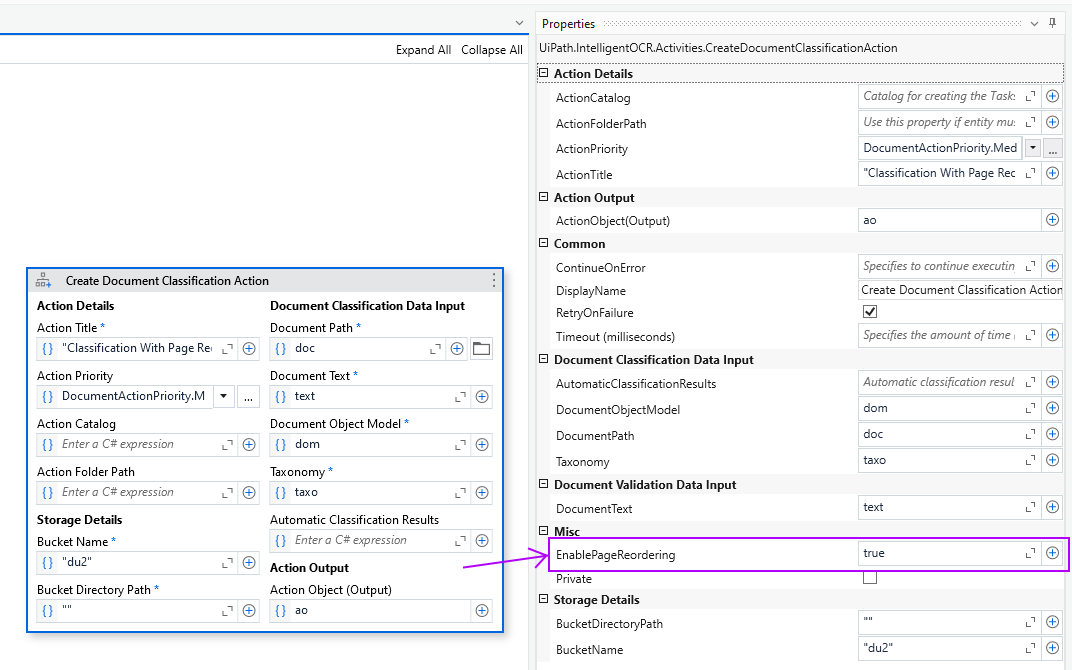
Once you do that,
- you can start dragging and dropping pages from any position to any other position
- you can start dragging and dropping sections (once separated) up and down - this is really useful if you really need documents incoming in a certain order in your automation
- you will notice the displayed document also shows you the pages in the “corrected” order, so that the human reviewing the document can see the final “order” of the pages in a natural flow and not have to do mental juggling

Important notes:
 Enabling Page Reordering DOES NOT alter the document being processed. It instead collects the correct page information in the ClassificationResult array output. You can then use that information (look for the PageRange new property of the result) to do what’s needed in your automation, or pass it along for data extraction, and the DataExtractionScope will know what to do with it
Enabling Page Reordering DOES NOT alter the document being processed. It instead collects the correct page information in the ClassificationResult array output. You can then use that information (look for the PageRange new property of the result) to do what’s needed in your automation, or pass it along for data extraction, and the DataExtractionScope will know what to do with it 
 This feature will also be available for the DocumentUnderstanding.Activities pack in a short while.
This feature will also be available for the DocumentUnderstanding.Activities pack in a short while. This is a preview package with a boatload of features, if you find any bugs please let us know and we’ll squash them before the GA release!
This is a preview package with a boatload of features, if you find any bugs please let us know and we’ll squash them before the GA release!
 Compact View in Validation Station
Compact View in Validation Station 
There’s almost no DU automation that doesn’t need human validation of extracted data at one point or another… And for high volume use cases, the Human Validators go through hundreds of documents a day. We’re now ready to present what we’ve been working on to make your lives easier! ![]()
First for the techies: update your IntelligentOCR.Activities pack to 6.25.0-preview or higher, go to the Create Document Validation Action or Present Validation Station activity, and set the DisplayMode input argument to Compact.
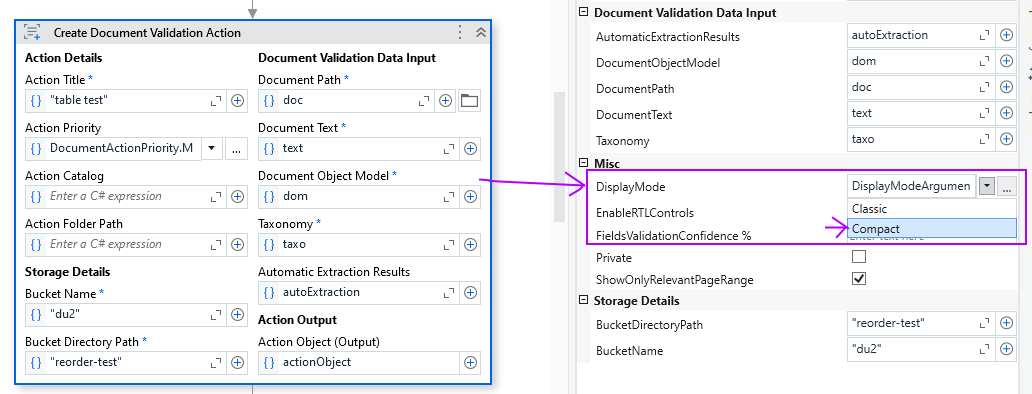
(![]() Oh, by the way, you can also enable Right-To-Left Languages controls as well! If set to true, the RTL options appear in Validation Station under a value’s three dots. They help the user with some display settings (right/left/auto align value), and with a shorthand for reversed extractions, “Reverse Words”.
Oh, by the way, you can also enable Right-To-Left Languages controls as well! If set to true, the RTL options appear in Validation Station under a value’s three dots. They help the user with some display settings (right/left/auto align value), and with a shorthand for reversed extractions, “Reverse Words”. ![]() )
)
… and this is what you get:
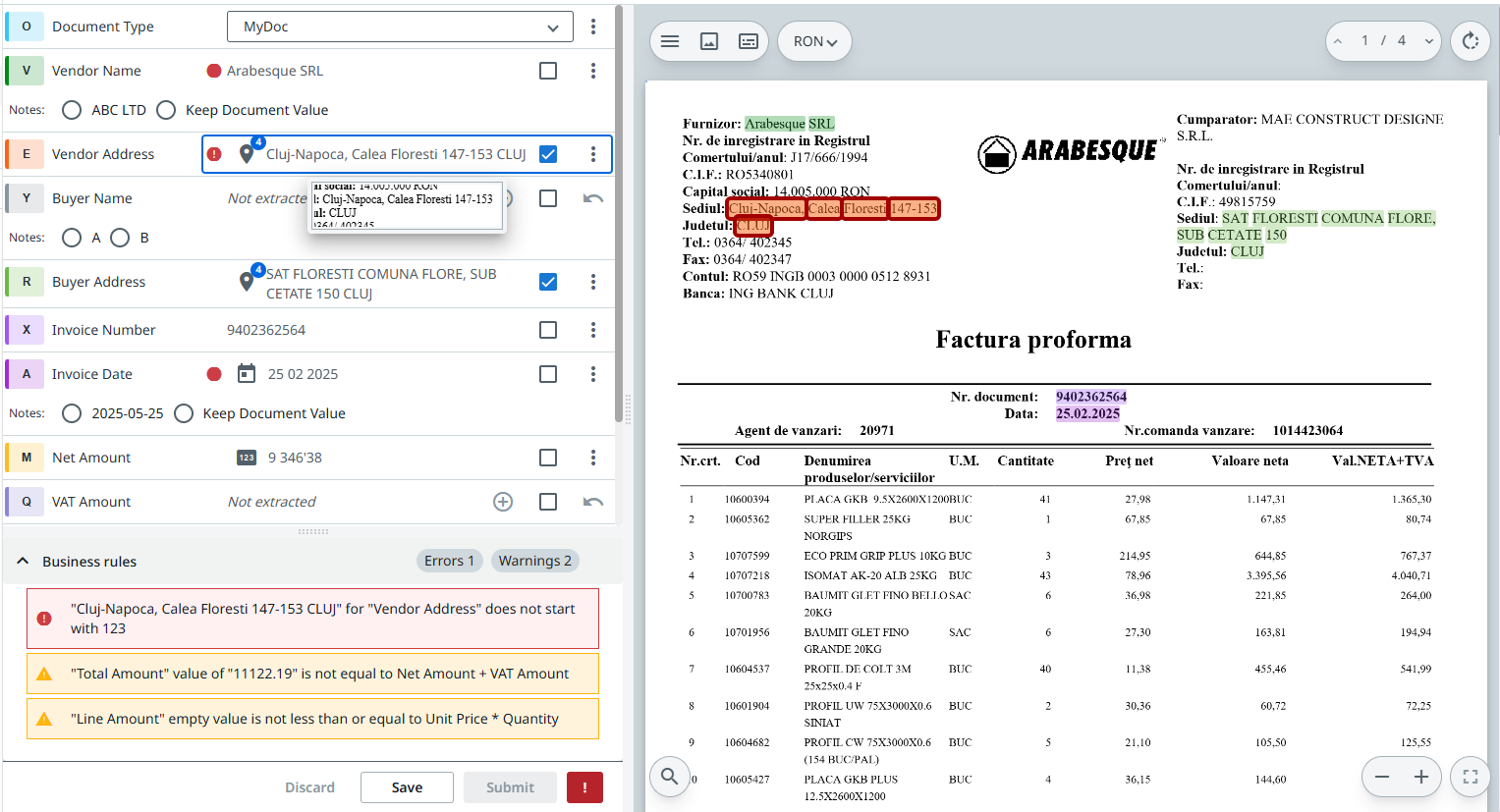
There are so many cool features, that I’ll just list them here in TLDR mode and let you discover them on your own. So some pointers:
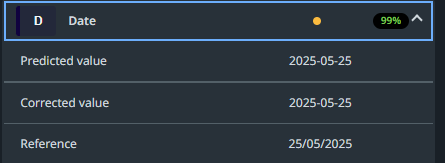
 number and date types are now enforced (a human cannot “forget” to fill in the parsed values, or accidentally enter something incorrect in any of these fields). Validators now also have a calendar picker next to date fields.
number and date types are now enforced (a human cannot “forget” to fill in the parsed values, or accidentally enter something incorrect in any of these fields). Validators now also have a calendar picker next to date fields. number and date fields have display settings! How do you want your date to look, dd/MM/yyyy, or maybe dd-MM, yyyy? No problemo, set it up proper and that’s how you’ll see them. Same for numbers, you can set the decimal and thousands separator to fit your needs.
number and date fields have display settings! How do you want your date to look, dd/MM/yyyy, or maybe dd-MM, yyyy? No problemo, set it up proper and that’s how you’ll see them. Same for numbers, you can set the decimal and thousands separator to fit your needs.
 red/green bullets: we hid the confidence levels: a human looking over thousands of fields shouldn’t do the mental effort of looking at the confidence and decide if something needs to be reviewed or not - you, the RPA dev, set that up at field level in Taxonomy manager. If either OCR confidence or value confidence are below the thresholds you set, the bullet is red. If any check (taxonomy business rule) fails, the bullet is red. Otherwise, it’s green!
red/green bullets: we hid the confidence levels: a human looking over thousands of fields shouldn’t do the mental effort of looking at the confidence and decide if something needs to be reviewed or not - you, the RPA dev, set that up at field level in Taxonomy manager. If either OCR confidence or value confidence are below the thresholds you set, the bullet is red. If any check (taxonomy business rule) fails, the bullet is red. Otherwise, it’s green!- screen space: values now inline with the field names if there’s enough screen real estate
 centralized checks view: below the fields list, you have a centralized view of all your failed business rules - clicking on one will focus the user directly on the field with issues!
centralized checks view: below the fields list, you have a centralized view of all your failed business rules - clicking on one will focus the user directly on the field with issues! partial table saves and goodies: seems small, right? yeah, unless you have 600 pages of a single table! We’ve completely redone table display and functionality, you can save your work partially for a table now, there’s markers showing you if there are any values failing validation (bad number or date for example) that take you directly to the cell with issue, there’s markers telling you how many cells you haven’t reviewed, as well as taking you to the first one (where you left off)… there color coding on table columns as well, and you do not need to visit all tables and manually confirm them anymore
partial table saves and goodies: seems small, right? yeah, unless you have 600 pages of a single table! We’ve completely redone table display and functionality, you can save your work partially for a table now, there’s markers showing you if there are any values failing validation (bad number or date for example) that take you directly to the cell with issue, there’s markers telling you how many cells you haven’t reviewed, as well as taking you to the first one (where you left off)… there color coding on table columns as well, and you do not need to visit all tables and manually confirm them anymore  ← confirmation is moved to the main Submit functionality.
← confirmation is moved to the main Submit functionality. structured exception reasons: you can now define in your taxonomy what exception reasons you want the user to choose from, so your automation picking up an exception is more deterministic.
structured exception reasons: you can now define in your taxonomy what exception reasons you want the user to choose from, so your automation picking up an exception is more deterministic.
(repeating myself just in case) ![]() This is a preview package with a boatload of features, if you find any bugs please let us know and we’ll squash them before the GA release!
This is a preview package with a boatload of features, if you find any bugs please let us know and we’ll squash them before the GA release!
 Redact Document Activity
Redact Document Activity 
And for you security enthusiasts, leaking data when making documents public is … never to be done, right?! ![]()
![]()
So here we are, coming to meet a more and more pressing concern: releasing public documents, with proper redaction in place.
We’ll start again with the tech-y side - the activity is in the IntelligentOCR.Activities pack 6.25.0-preview or higher, and it looks like this:
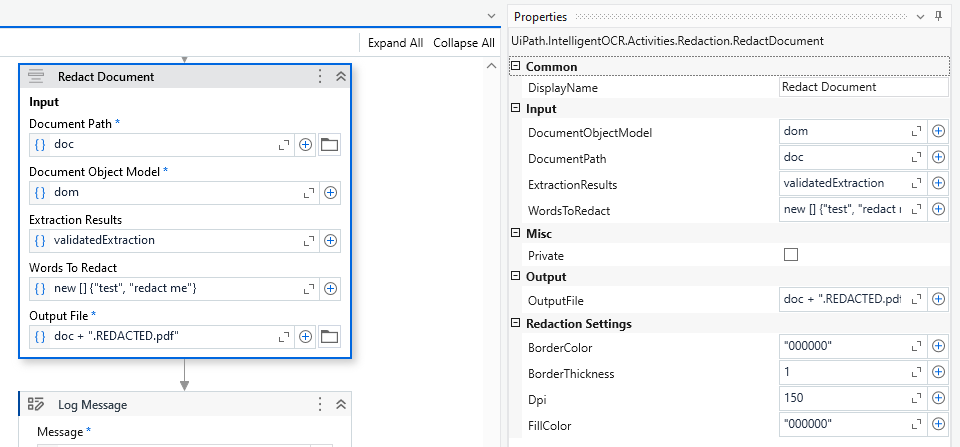
Properties you need to understand:
- document path and document object model - you already know. Obviously you’ll need to digitize the file to get the DOM, right?
- ExtractionResults - just that. Will be used by the activity to know WHAT to redact. (more below
 ). This is obtained from the Data Extraction Scope or from a Human Validation activity.
). This is obtained from the Data Extraction Scope or from a Human Validation activity. - WordsToRedact - just that. Actually expressions. It is an array of strings that will be used by the activity to know WHAT ELSE to redact, generically. (more below )
- Output file - where to save the new redacted pdf
- Redaction Settings - fill color, border color and thickness, should be self explanatory - DPI, though, is not. (more below )
Aaand we’re below, so here’s how the activity works:
- it renders each page of the incoming PDF as an image of the set DPI
- it redacts everything that is in the extraction results as values (regular fields and table cells included), for all values that have a reference (
 )
) - it redacts ALL INSTANCES of every value in the extraction results that DOES NOT have a reference (
 )
) - it redacts ALL INSTANCES of every expression in the WordsToRedact string array (can be multiple words, yes) ()
- it generates a new PDF in which each page will be the redacted image of the original PDF page. To make sure absolutely nothing might be missed during redaction.

Some useful notes and warning:
- We strongly recommend that, except for weird cases, you use Validation Station before redaction, to make sure ALL instances that require redaction are captured. Blindly redacting something is bad practice.
- ← this above is almost like “blindly redacting something”. Using values with no reference and WordsToRedact would be more appropriate as a “fail-over” method instead of as a main method of marking what needs to be redacted. This is because matching over the document object model is not guaranteed to be perfect (things might be far apart, badly OCRed, might have variations you haven’t captured, etc).
 Use multi-value fields if you want to capture a list of things, or for generic ToBeRedactedAnyway type of content capturing. Whether extracted automatically and just validated, or manually input by the human, this is particularly powerful in long documents with unknown numbers of occurrences for a given value.
Use multi-value fields if you want to capture a list of things, or for generic ToBeRedactedAnyway type of content capturing. Whether extracted automatically and just validated, or manually input by the human, this is particularly powerful in long documents with unknown numbers of occurrences for a given value.
 Modern Projects Retraining
Modern Projects Retraining
You can now use validated information to improve your Modern Project extractor!
The mechanism is very simple:
 extract something
extract something- validate it in Action Center
 (IntelligentOCR.Activities) send the data back to the project
(IntelligentOCR.Activities) send the data back to the project- view corrected information and push documents of your choice into the Build phase to trigger retraining of the models.
We won’t explain (1) and (2), you’re here because you’re already doing it ![]()
So on to (3) ![]() :
:
- for DocumentUnderstanding.Activities users: when the Modern project, the robot and the Action Center are on the same tenant, you won’t need to do anything. Just move directly to (4). When you are using a hybrid scenario, currently this won’t work. It will, starting end of July and the next preview activity package though.
- for IntelligentOCR.Activities users: use Train Extractors Scope with DU Project Extractor Trainer properly configured, to push data back (same-tenant or hybrid scenario regardless) to the Modern Project Monitor section.
Like this:
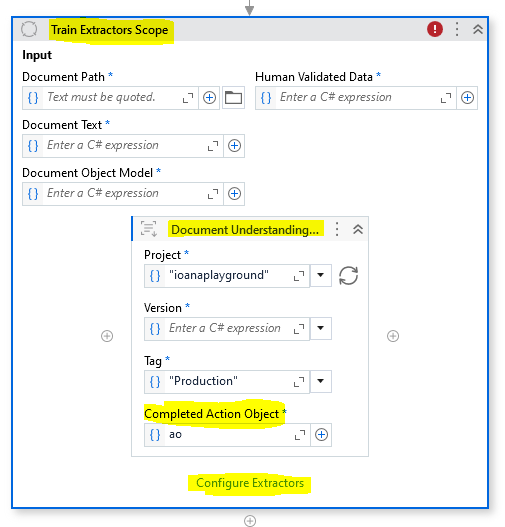
Please don’t forget to Configure the Scope properly. Also please don’t forget to save and input your completed action object as well - so that in Monitor you’ll have all the data related to the task management part.
Important note: You can only send data back to the custom project you extracted it with.
Now for the cool part ![]()
![]() :
:
Once validated information reaches Monitor, there’s a cute little button that appears in Build next to each document type that does have corrected data. It’s called Exceptions for Review. That’s where you can view which documents and which corrections were touched by the human validator, and decide whether a particular document should go into the Build phase to trigger retraining or not.
Here’s how it looks:

and (once you click it)
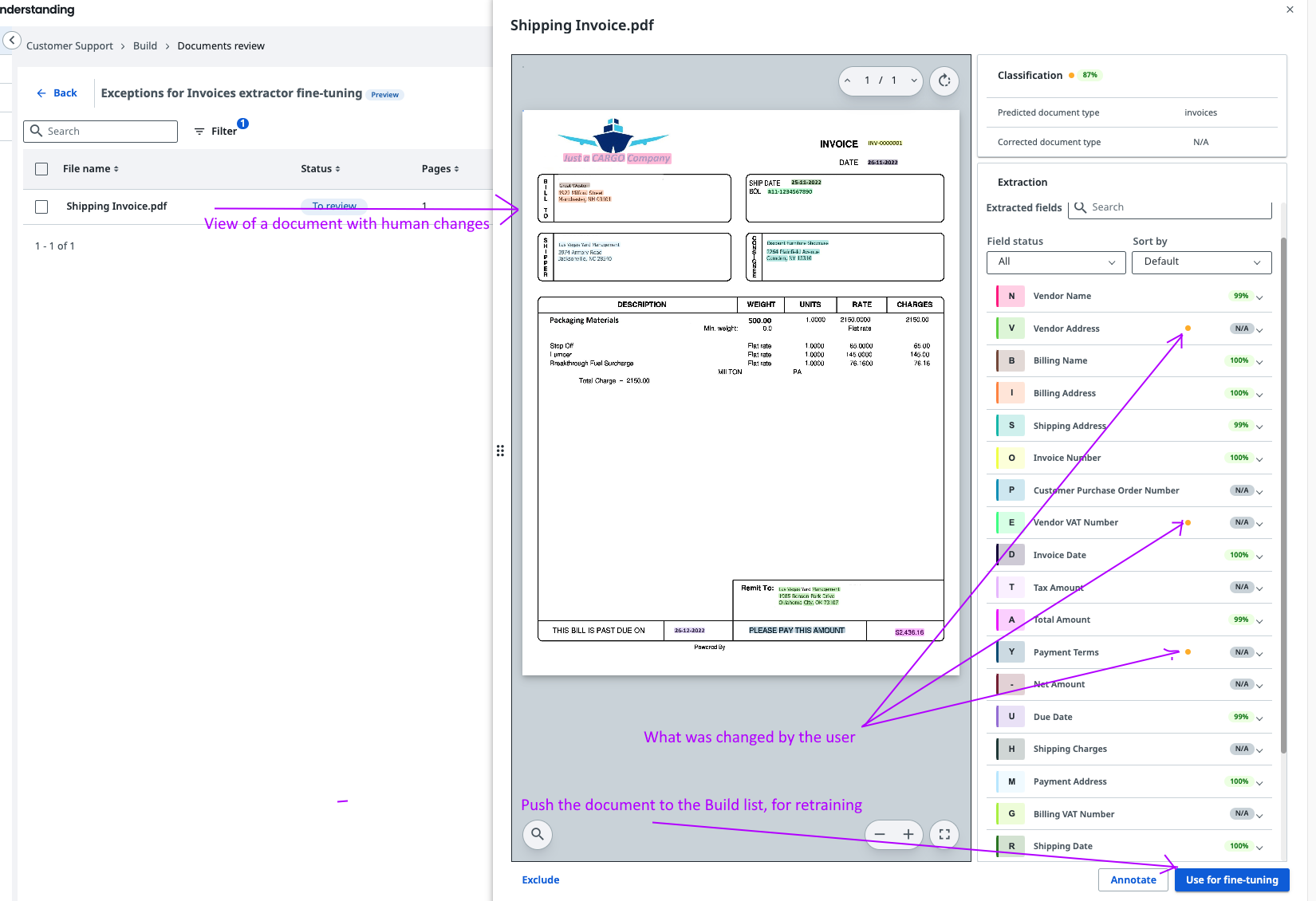
Make sure to read the full documentation about the retraining feature and have fun trying it out!
AI Units dashboards improvements
We have enhanced the existing AI Unit dashboards bringing greater transparency, and broader coverage into how AI Units are consumed across your organization.
With this update, your AI Unit telemetry experience is getting three key enhancements:
1. Track AI Unit Consumption via API Key-Based Activity Usage
We have enhanced the “Organization level overview dashboard” expanding visibility to include AI Units used at the organization level through activities authenticated with API Keys—such as:
- Machine Learning Extractor
- Form Extractor
- Other activities in this authentication scenario
2. Communications Mining Consumption
AI Unit consumption from Communications Mining is now included in all 3 AI Units dashboards. You can now track consumption coming from Communications Mining projects, data sources and operations, including dedicated widgets in the product-specific IXP Dashboard (previously known as “Document Understanding & AI Center dashboard”) for a better understanding of consumption insights:

3. ![]() ‘Unknown’ causes
‘Unknown’ causes
When AI Unit consumption entries are marked as ‘unknown’, the dashboard will now display possible causes for the missing data points—making it easier to troubleshoot and identify where the usage is coming from. We have also prepared this troubleshooting guide for you to better understand where the unknowns come from and how to act on them ![]()
Document Understanding in the Platform Audit
So you have visibility into the user actions happening in Document Understanding at design time (e.g. projects created, project version deployed etc.), we now provide the respective events in the tenant-based Audit Logs of the Platform:

We’re excited to see how these improvements will help you drive even more value from your AI-powered automations! As always, we welcome your feedback. ![]()
— The Document Understanding Team