初めまして、UiPathやweb系に関しては初心者のものです。
例えば以下のような厚生労働省のページでpdfファイルのみを全てダウンロードするにはどのようにしたらよいでしょうか?
http要求というアクティビティを用いるとよい、と書いてあるサイトはあったのですが
具体的な使い方が分かりませんでした。
丸投げな質問になってしまい申し訳ないですが、よろしくお願いいたします。
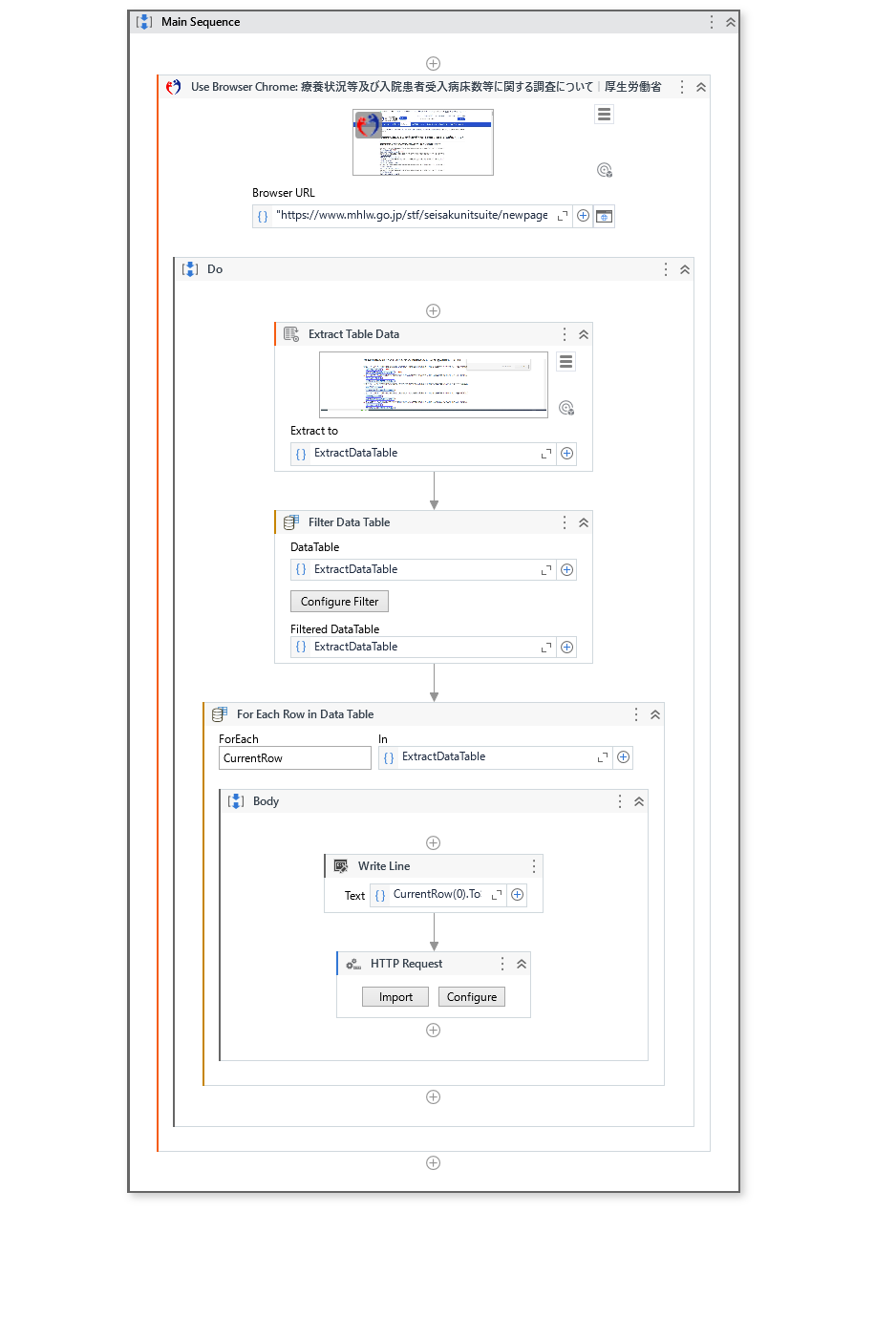
早速のご回答ありがとうございます。
webページを表データとして抽出して、フィルターでpdfのみにするといった方法でしょうか。
さらに質問なのですが、一行を書き込みではどのような書き込みをしているのでしょうか?
また、httpリクエストウィザードの詳細な設定方法を教えていただきたいです。(もしあれば詳細な設定方法が書いてあるページでも構いません。)
よろしくお願いいたします。


こんにちは
単にURLが想定通りに取得できているかの確認のため、出力しているだけのものになります。
(ので動作そのものには直接関係はありません)
httpリクエストウィザードの詳細な設定方法を教えていただきたいです。
今回のケースでいうとWizardは使用していません。
Request URLにアクセス先のURLを
Filename for response attachment にダウロードした結果を格納するファイル名を
それぞれ記載するだけです。
なお、HTTP Request アクティビティをフル活用するとなると、それなりにHTTPあるいは
Webに関する通信の知識が必要になります。

ご丁寧にありがとうございます。
自分の環境でも正常に動作しました。
また、zipファイルを付けていただいていたことに気づきませんでした。
ありがとうございます。
1 Like
This topic was automatically closed 3 days after the last reply. New replies are no longer allowed.