Dear Community,
I am unable to train the ML Package - EnglishTextClassification via Pipeline.
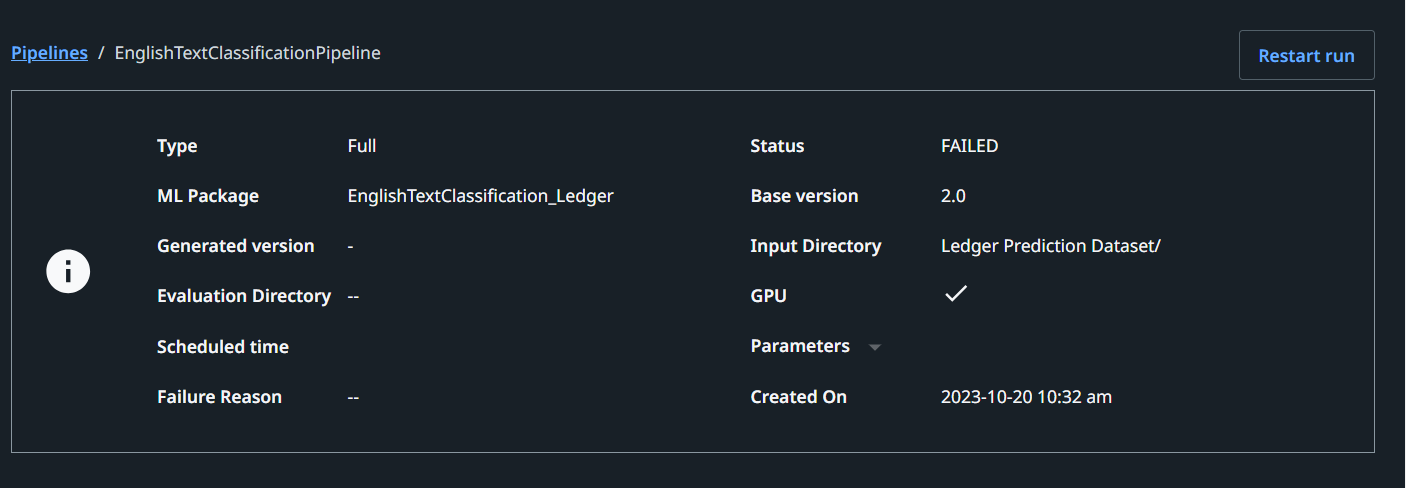
Getting an error - Failed due to package issue.
Adding ML logs below for reference,
Traceback (most recent call last):
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/trainer_run.py”, line 95, in main
wrapper.run()
File “/microservice/training_wrapper.py”, line 58, in run
return self.training_plugin.model_run()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 195, in model_run
raise ex
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 167, in model_run
self.run_full_training()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 212, in run_full_training
self.process_data()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 530, in process_data
raise e
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 527, in process_data
self.process_data_model(self.local_dataset_directory)
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 152, in process_data_model
response = self.model.process_data(directory)
File “/microservice/train.py”, line 17, in process_data
self.model.process_data(directory)
File “/microservice/aiflib/model.py”, line 166, in process_data
raise UiPathUsageException(‘No valid data to run this pipeline.’)
aiflib.logger.UiPathUsageException: No valid data to run this pipeline.
Traceback (most recent call last):
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/trainer_run.py”, line 101, in main
raise e
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/trainer_run.py”, line 95, in main
wrapper.run()
File “/microservice/training_wrapper.py”, line 58, in run
return self.training_plugin.model_run()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 195, in model_run
raise ex
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 167, in model_run
self.run_full_training()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 212, in run_full_training
self.process_data()
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 530, in process_data
raise e
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 527, in process_data
self.process_data_model(self.local_dataset_directory)
File “/home/aicenter/.local/lib/python3.6/site-packages/UiPath_core/training_plugin.py”, line 152, in process_data_model
response = self.model.process_data(directory)
File “/microservice/train.py”, line 17, in process_data
self.model.process_data(directory)
File “/microservice/aiflib/model.py”, line 166, in process_data
raise UiPathUsageException(‘No valid data to run this pipeline.’)
aiflib.logger.UiPathUsageException: No valid data to run this pipeline.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/usr/local/lib/python3.6/site-packages/azure/storage/blob/_blob_client.py”, line 683, in delete_blob
self._client.blob.delete(**options)
File “/usr/local/lib/python3.6/site-packages/azure/storage/blob/_generated/operations/_blob_operations.py”, line 514, in delete
raise models.StorageErrorException(response, self._deserialize)
azure.storage.blob._generated.models._models_py3.StorageErrorException: Operation returned an invalid status ‘The specified blob does not exist.’
Content: <?xml version="1.0" encoding="utf-8"?>BlobNotFoundThe specified blob does not exist.
RequestId:9fc09980-501e-0029-711a-031b6d000000
Time:2023-10-20T05:56:18.2886086Z
During handling of the above exception, another exception occurred:
Traceback (most recent ca… (truncated).
