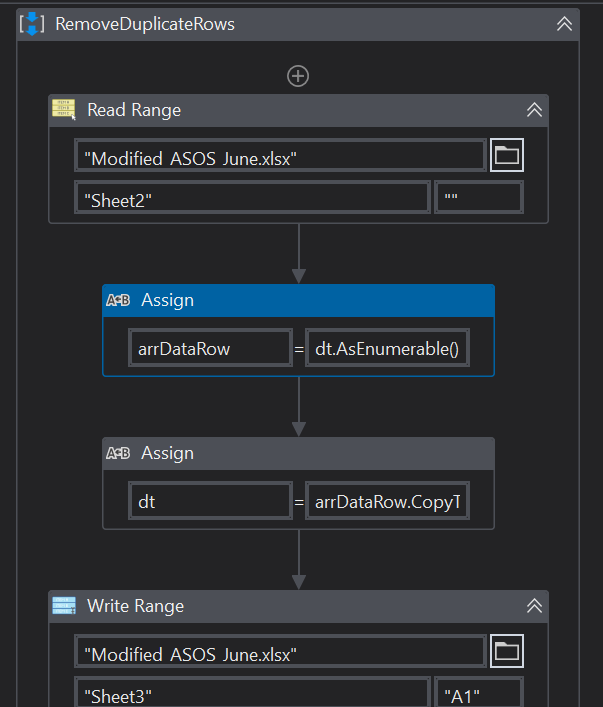
Remove all duplicate rows based on the column named “PO”.
Keep all the duplicate rows ONLY based on the column named “PO”.
I tried the first part to remove duplicate rows but it is keeping a record of one of each row and and deleting the rest.
I used this:
dt.AsEnumerable().GroupBy(Function(x) convert.ToString(x.Field(of object)(“PO”))).SelectMany(function(gp) gp.ToArray().Take(1))
You can use LINQ statements to do remove dups.
Like dt.AsEnumerable().GroupBy(Function(r) r.Field(of String)("<Col Name>")).Select(Function(s) s.First()).CopyToDataTable - This can be used to remove all dups with in the specified column.
dt.DefaultView.ToTable(True) - It will create a new Datatable with unique rows with respect to every column.
You can group unique values (removing duplicates) for each column and finally update them in a new table.
Example:
Build DataTable with duplicates: vDt1
Note: vDt2 is a copy of vDt1 but empty
For each(): List of items= vDT1.AsEnumerable().GroupBy(Function(x) x(“Valor1”).ToString) Item: groupby_result
Body:
First, you have to analyze if there are rows in the vDt1 <= Number of item of the group
If : vDt1.Rows.Count <= vIntRowValue
Then: ADD DataRow with empy values
Finally Assign:
vDtDatosOCR.Rows(vIntRowValue)(“Value1”) = groupby_result.Key.ToString