I have completed some of the basics in handling the UiPath Software through the UiPath Academy but I feel more a noob than a rookie trying to solve some real issues. So, guide me through this marvellous RPA software. and thank you in advance
In an attached file I presented the type of data in PDF I am mining/scraping. The data are inside the tables in which occasionally has images and tables inside them.
1st issue - per definition this is considered structured data ou unstructured data? Due to the nature of this particular data set aroused some doubts…
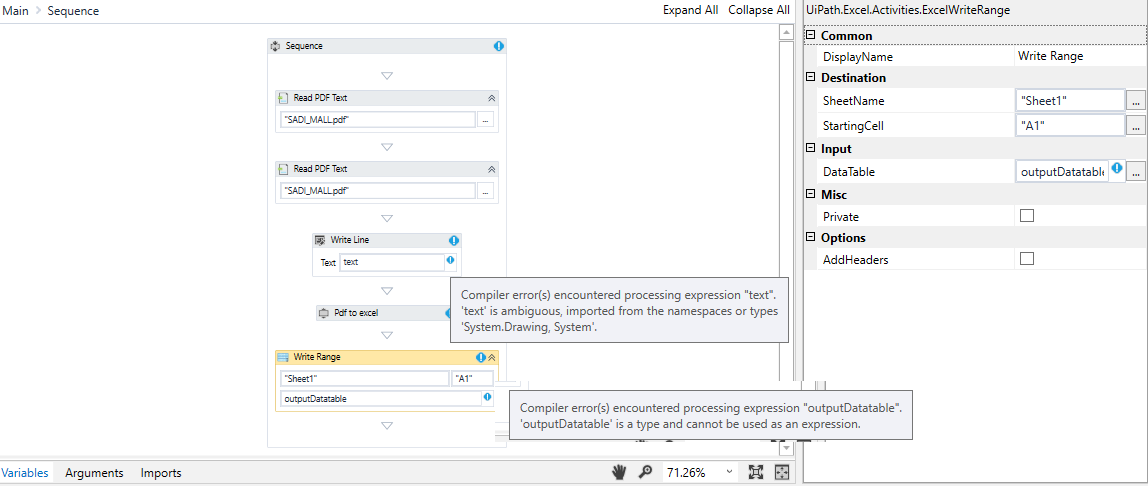
2nd issue - what the best activities/methods for this particular case? I try the following: Screen Scraping, Read PDF, PDF to Excel (as a suggested package) and Write Range…I could not get the desired outcome.
The next file is my attempt to extract the data to put in Excel…however, it seems to me that I lack some understanding in both basics workflows and advanced features in some of activities/methods (?!)
Thank you for your reply, I am grateful for that link and I will read carefully.
Accordingly, with a list I have, the documentation is between 150 PDFs and 300 documents from other sources. And yes, the structure is the same with a header detailing the origin of the information.
Why you are asking about this? Could affected the desired outcome?
I was wondering just because looks to me like a messy structure. But if all your documents are the same you should be able to get all the information without problem.
As a completion to Carmen’s answer it seems that your pdf has structured data after all. There is no clear recipe to extract the data, trial and error works best when you are a rookie (at least this is how i learned).
I think Lesson 3 - Data Manipulation & Lesson 10 - PDF might shed some light on a high level of extracting the data.
Try Carmen’s suggestions first, it’s a good idea and let us know what specific issues you encounter.
I insert the pdf file in question (with authorization from my boss and well what I was trying to do), I did have two weeks on this only, due to other tasks I must attend at company.