I’m trying to extract Invoice number, PO Number and Invoice Amount from an invoice PDF. Get OCR Text (including anchor base) returns an error “Scrape Returns empty text”, irrespective of using Google OCR or Microsoft OCR.
I attempted the following, which returned positive result
Read PDF Text & Read PDF with OCR. But these activities are not useful, as I’m looking for specific details in invoice.
Indicating the clipping region before every execution gives text. However, on closing and reopening the file, I get the same error. (Tried adjusting scale to avoid different resolution/ zoom level errors with vain)
Read other posts on this topic, but solutions are provided only to handle this error as exception through try/catch. But I need to extract these values.
Please provide your suggestion to resolve the issue and extract data successfully
This is just from my experience, but if you change the scale when that error occurs, the error doesn’t happen. What I had to do was decrease the scale each time it fails in like a Do While loop. Therefore, the scale is more dynamic based on if there is an error.
Sorry can’t provide a sample, but hope this helps.
If changing scale never resolves the issue, then you just need to assume there is no text. Not sure, if there is indeed text, though.
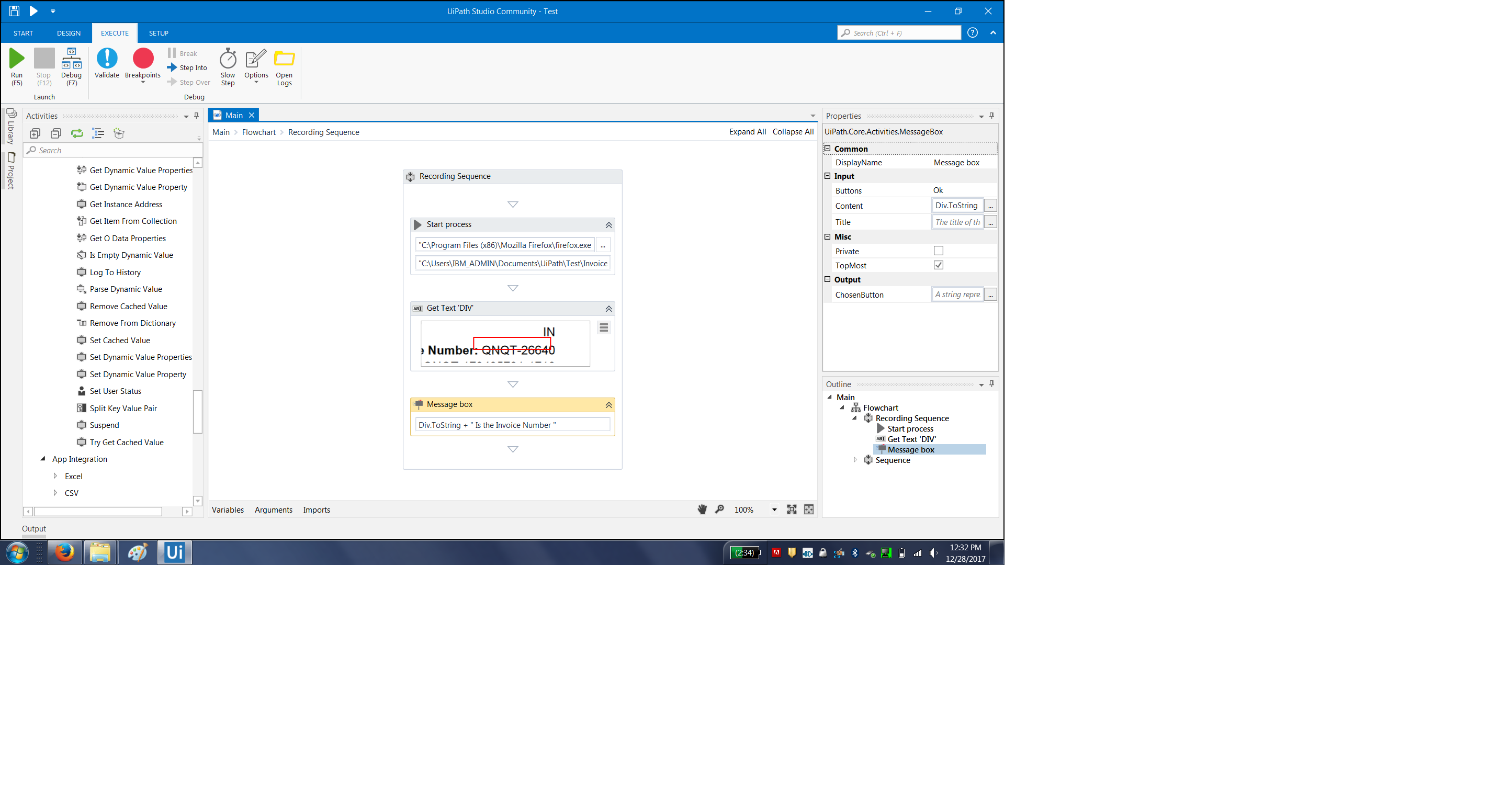
I tried to get the Invoice Number from sample Invoice.pdf (i used a sample invoice.pdf file from Amazon), and I will able to get the specific values , store them in variable and display it as well.
Could you please try this
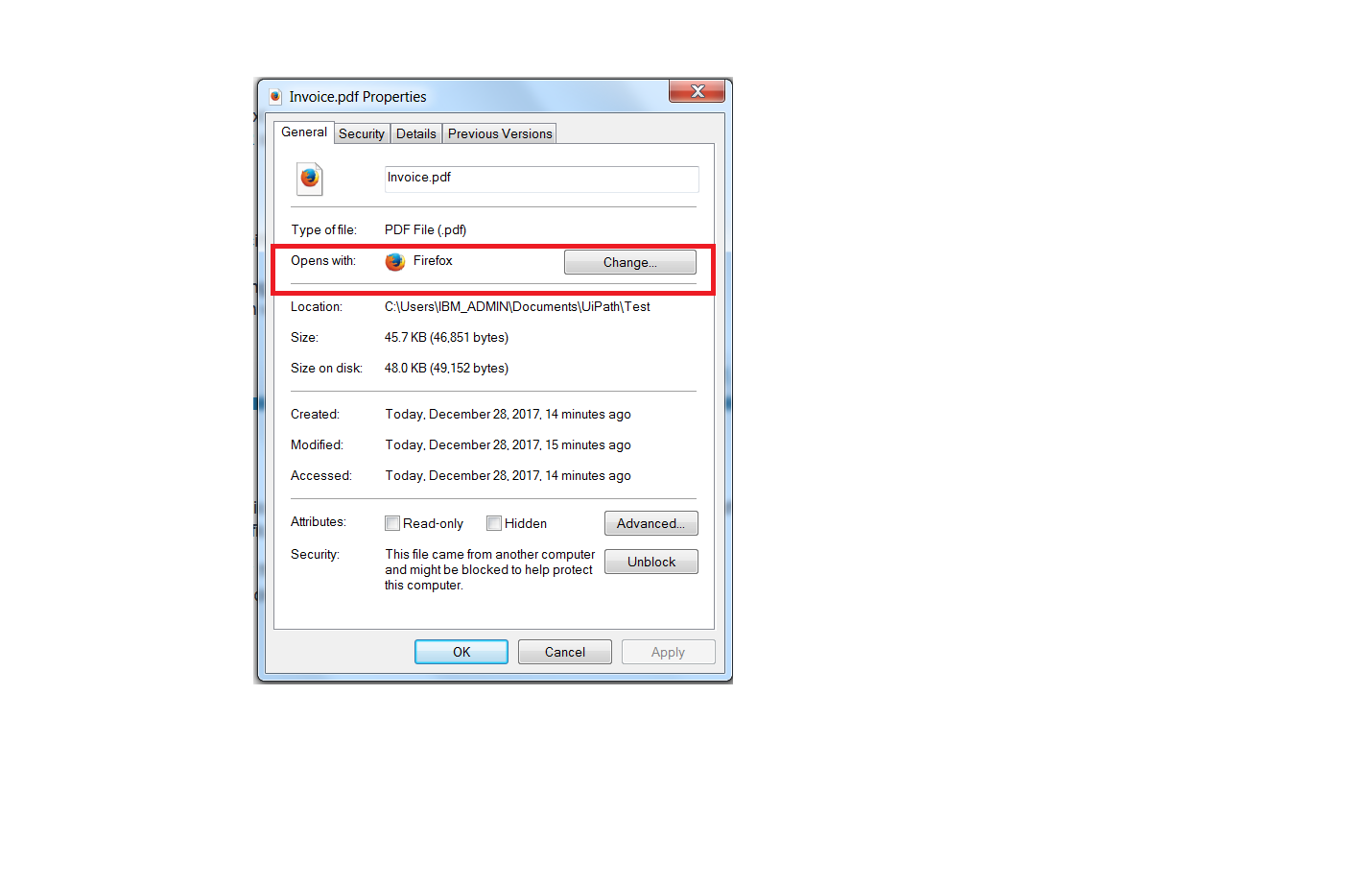
1.> Manually right click on the Invoice.pdf and click properties
then change open with to Firefox
a.> Use Start process activity and give the path as installation directory of Firefox something like “C:\Program Files (x86)\Mozilla Firefox\firefox.exe”
b.>manually double click the invoice.pdf and it will open through firefox.
copy the address of that pdf file from address bar , something like “C:\Users\XYZ\Documents\UiPath\Test\Invoice.pdf”
c.> Put that in start process second text box.
Once the file is opened on browser, I think u can get each and every detail properly using get text activity.
Thanks Clayton for the suggestion. I manually tried changing the scale but didn’t get me the result unfortunately. And definitely there is text, because Read PDF or Read PDF with OCR is getting me the text from full file.
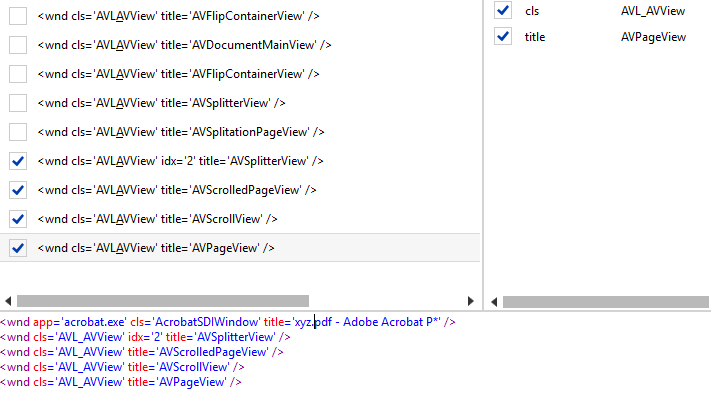
I’m confused as why the file is not giving full selector. In Anchor base, while I use Find Image or Find Element, the selector appears as
and the Get Text activity selector is
(In Ui Explorer, the entire region gets highlighted as Image and unable to look into specific text element of the PDF)
With Clipping region, for that particular execution robots returns result. If I scroll the page up/ down (even slightly) or reopen the same file again, scraping does not return any text.
Being an official invoice I’m unable to share a copy of it. However, I hope to have explained my issue. Please help me on this