In a folder if I have both scanned pdfs and pdfs how to extract from both pdfs with one code.how to extract the text and save in excel.
You can use Read PDF with OCR activity. This will extract text for both scanned pdfs and PDFs and use Regular Expressions to extract the required data to write the data to excel.
Regards
while extracting the text in scanned pdfs , If i didnt specify correct size then iam getting error as empty but every pdf file filed text has different sizes
Can you share the PDF’s which has different font size, if it doesn’t has confidential information.
Regards
it is confidential information
iam getting empty I have used regex
Can you help me with the regex for this same pdf
wordpress.pdf (42.6 KB)
my invoice is scanned pdf
Invoice Number
Order Number
Invoice Date
Due Date
1 Like
Check out the below workflow:
Sequence21.xaml (13.4 KB)

So, below are the specifications:
In Read PDF with OCR change the Image DPI from 150 to 270

In Tesseract OCR engine the scaling field will be empty so give 2.5
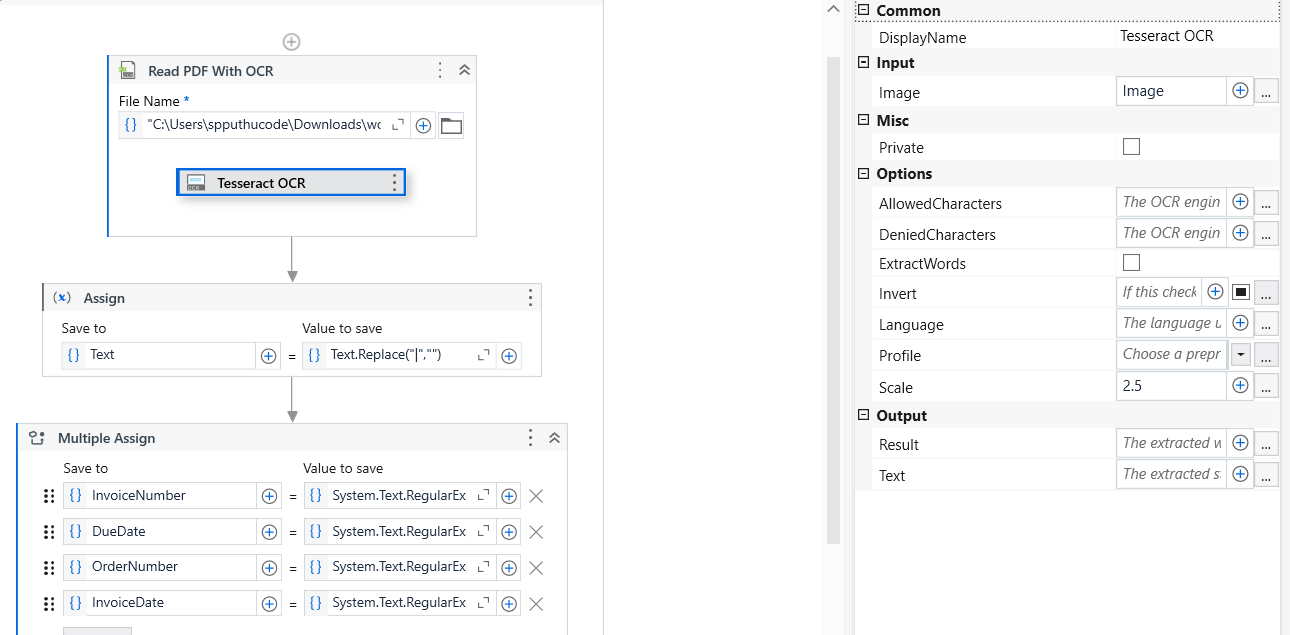
When you write your data to text file you will get | symbols, so replace that particular | with empty.

Hope you understand!! @anjani_priya
![]()
IAM GETTING THESE SYMBOLS IN THE OUTPUT
IAM GETTING MANY OTHER SYMBOLS IN THE OUTPUT