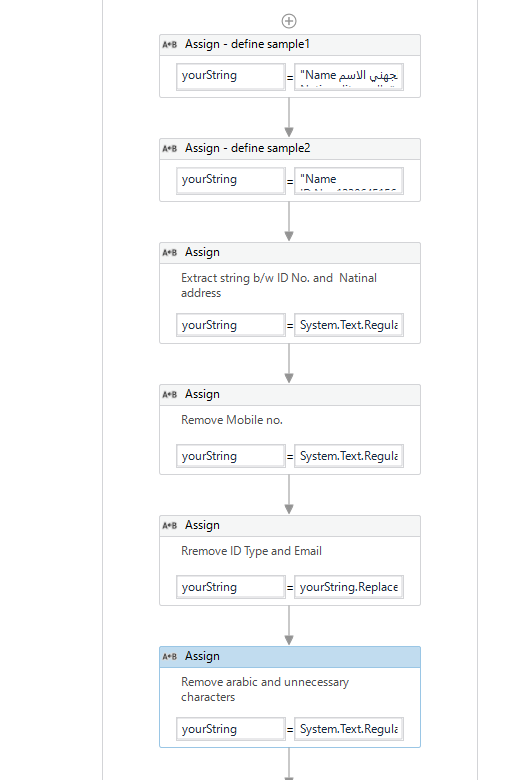
I have a pdf from which I need to extract a specific email address. The pdf contains data in English and Arabic language hence after read pdf activity the text that I receive is something like this:
case 1:
"
Name مصلح مسعد عواد الجهني الاسم:
Nationality المملكة العربية َّسية: الجن
السعودية
ID No. 1346795643 َّوية: رقم اله ID Type هوية وطنية َّوية: نوع اله
Email john2010@gmail. البريد الإلكتروني: Mobile No. +966123564785 َّرقم الجوال: com
National Address "
case 2:
"
Name
ID No. 1230645156 john@ya
Email hoo.com.u k
National Address
فهد عبدالعزيز فهد الحكير
Nationality
َّوية: رقم اله ID Type
البريد الإلكتروني: Mobile No.
الرياض, الرياض
تاريخ الانتهاء تاريخ الاصدار "
I have mentioned the email id in Bold : case1 email should be - john2010@gmail.com, case 2 email should be - john@yahoo.com.uk
The reason for such structure is, the pdf gets disorganized after being converted to string.
Appreciate any help using string manipulation or regex.
However, it might be get incorrect address if input string structure is different from the sample.
It may be good to consider to use DocumentUnderstanding framework.