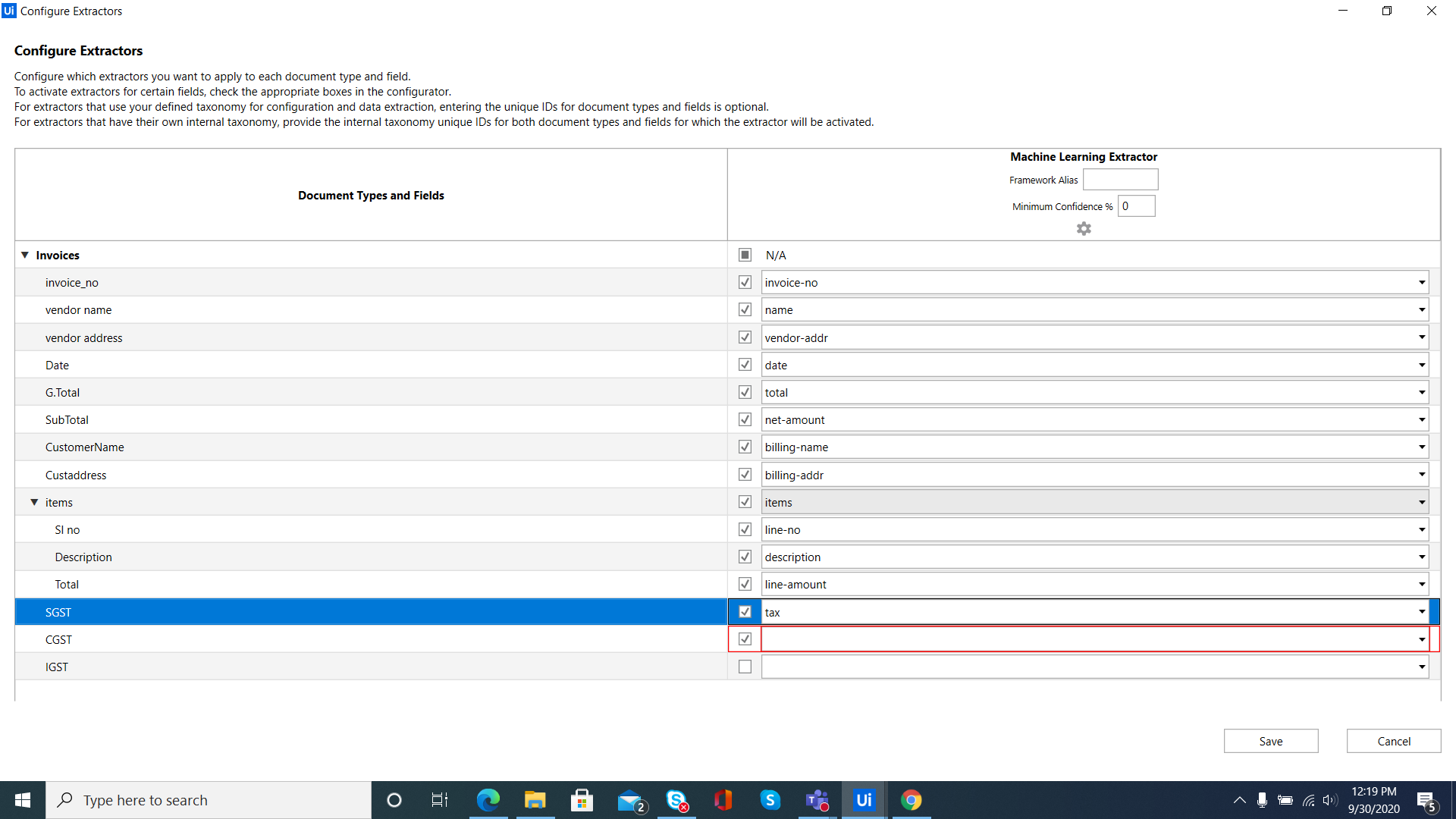
am using machine learning extractor to extract the fields from pdf. i have SGST, CGST and IGST in my pdf. am not able to configure the all three tax fields with internal taxonomy tax fields. and also not able to extract the address and total amount fields fully (only 2 lines in address and first two numbers in total amount am getting).
can anyone please help me on this, howw can i extract all those things.
If you are using an on prem orchestrator then address and total amount can be trained using data manager and the extractor trainer scope. If not, unfortunately there is no way at this time to train extractors in the community or cloud editions, but from my discussions in the past, UiPath is planning on implementing this hopefully in the next couple months for the cloud accounts.
Also, unfortunately the machine learning extractor cannot extract values that it doesn’t not have built in. If you want a machine extractor to pull these, you will need up upload your own custom extractor.
The easier option for both of these scenarios is to use multiple different extractors. You could try using one of the other extractors in tandem and extract only those values with it. I do understand that this is limited as the values must follow a pattern, but you could try using a regex extractor if the locations of these variables change, or a form extractor if they do not change locations.
Creating your own custom extractor requires python programming knowledge because you are creating your own Machine Learning tool. If you wish to know more about this, documentation on the structure and requirements for the python files can be found here: