Hi,
How to Split the pdf files basis on text (for ex 30 pages in some page i want text name 2-4 one pdf file and 5 -9 another pdf file basis on text name )
Thanks,
Hi,
How to Split the pdf files basis on text (for ex 30 pages in some page i want text name 2-4 one pdf file and 5 -9 another pdf file basis on text name )
Thanks,
Hi @upendra_koneru,
Please help me understand better what you need.
@GreenTea
please find the answer below
Thanks,
Hi @upendra_koneru,
This use case is tricky. The example provided is dependent on how well the RegEx pattern is crafted by you. Since I do not have the pdf file, you have to provide anchors and ensure the correct page boundaries are identified - not just the key words.
The idea:
Note: activity Assign Regex Pattern is to replace a space with \s for regular expression to work correctly. You will need to change it accordingly for the text you are searching
The example contains a sample pdf which you can test to verify the workings…
PDFExtract.zip (102.5 KB)
Hi @GreenTea
Thanks for your response
Can have the regex pattern for the value " **AER = Adverse Reaction Report "
Note: Text value is constant
Thanks,
Hi @GreenTea
Above code is not working for reference i am sending screenshot
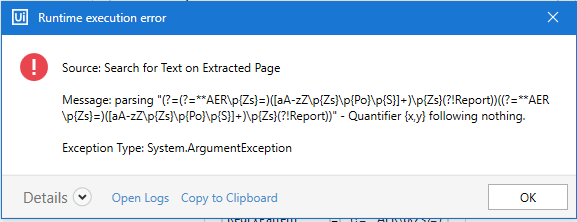
Thanks,
Hi @upendra_koneru,
Sorry, I see the issue. I have to enter two backslash \\ in the Forum to make the single backslash \ appeared. Follow the value shown in the image
(?=\*\*AER\p{Zs}=)([aA-zZ\p{Zs}\p{Po}\p{S}]+)\p{Zs}(?!Report)
Please use the 'UiPath.PDF.Activities.PDF.ExtractPDFPageRange` for slitting PDF files from bigger file
Extracts a specified range of pages from a PDF document.
This was helpful, but i have lil different usecase where i need to split pdf from main PDF where range is like inbetween of two fixed string. 1st page has word “Page1” and 5th page has word “Page1” i need to split pdf from 1-4. This has to be done for 300 page pdf. Range is not constant. Pls help
Hi @kartik_m - I have developed a code which does exactly the same stuff…
This program looks for the text and when there is a match it create a string and I am keep building the string as shown below…and then finally pass it to PDF Splitter (Bala Reva) or You can use Extract PDF Range activity also…

so this will split the pages in one shot as shown below…

Let me know, are you looking for something like this…
Hi @kartik_m
Since @prasath17 has a solution already, give it a try.
May i know how you are building string, If you share me xml of same, it would be great help.
@GreenTea is there a way to achieve using matches or regex?
@kartik_m - Please find the attached workflow
Split_PDF_Match.zip (761.6 KB)
If run this as is, you will see 3 files created under splitted Files folder.
Hope this helps…
Yes @prasath17 it is almost helped but strucked in one of logic where,
Page1
Page2- has word “Last page”
Document 1
Document 2
Page1- has the word “Last page”
Document1
Page1- has the word “Last page”
Document1
This is my main pdf format, and i need to split first 4, next 2 and 2. so i am referring the word “Last Page” and working out, but when page 2 has the reference word. there i am struck where i miss page1 in the split pdf. it considers only 2nd page as per our logic.
@kartik_m - I got it.Let me see if I can tweak the code…

Yes @prasath17 Please, And i cant take page1 as reference as even “Document1, Document2” has the word Page1. so to identify slot we need to go with word Last page.
And pls suggest how to name the split pdfs. I need to name individual pdf with “Data within it” like if page1 has invoice no in it. spit pdf name should be named as “InvoiceNo.pdf”
@kartik_m - I guess it is fixed…Now the text which I am looking for is found on page 2 and Page 6…so below are my page split…

Updated xaml:
Main.xaml (38.2 KB)
Please let me know if this is working for you…
@prasath17 , its working for first slot, not working for the inbetween slots.
Page1,- Getting this included
Page2,
Doc,
Doc,
Page1,
Doc,
Page1, - missing this again and making entire range disturbed
Page2,
Doc
Doc,
can we do like “if ‘page2’ word found” then (initialRange-1).
