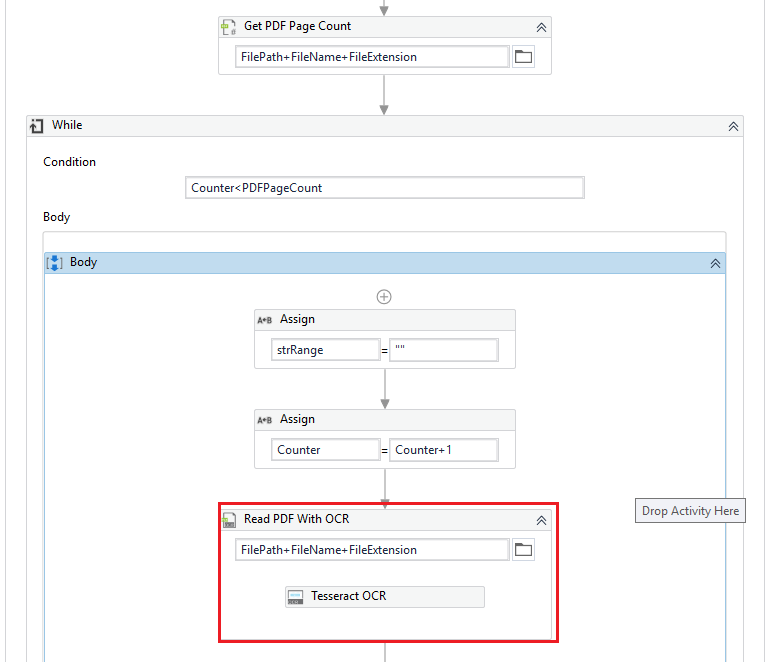
Description: I have one folder contains some pdf files, each pdf files contains many pages, some page contain “Voucher NO”, some page did not contain “Voucher NO”, EG: 223344 appear in first page and spread page to 4, 876876 appear in fifth page and spread page to 10
Requirement: I need to read each pdf per page, get string and check whether the string contain “Voucher NO”, and save as pdf per “Voucher NO” which need contain spread pages.
EG: 223344.pdf contain page 1-4, 876876.pdf contain page 5-10
Remark: I read several similar articles in the forum and didn’t find the answer
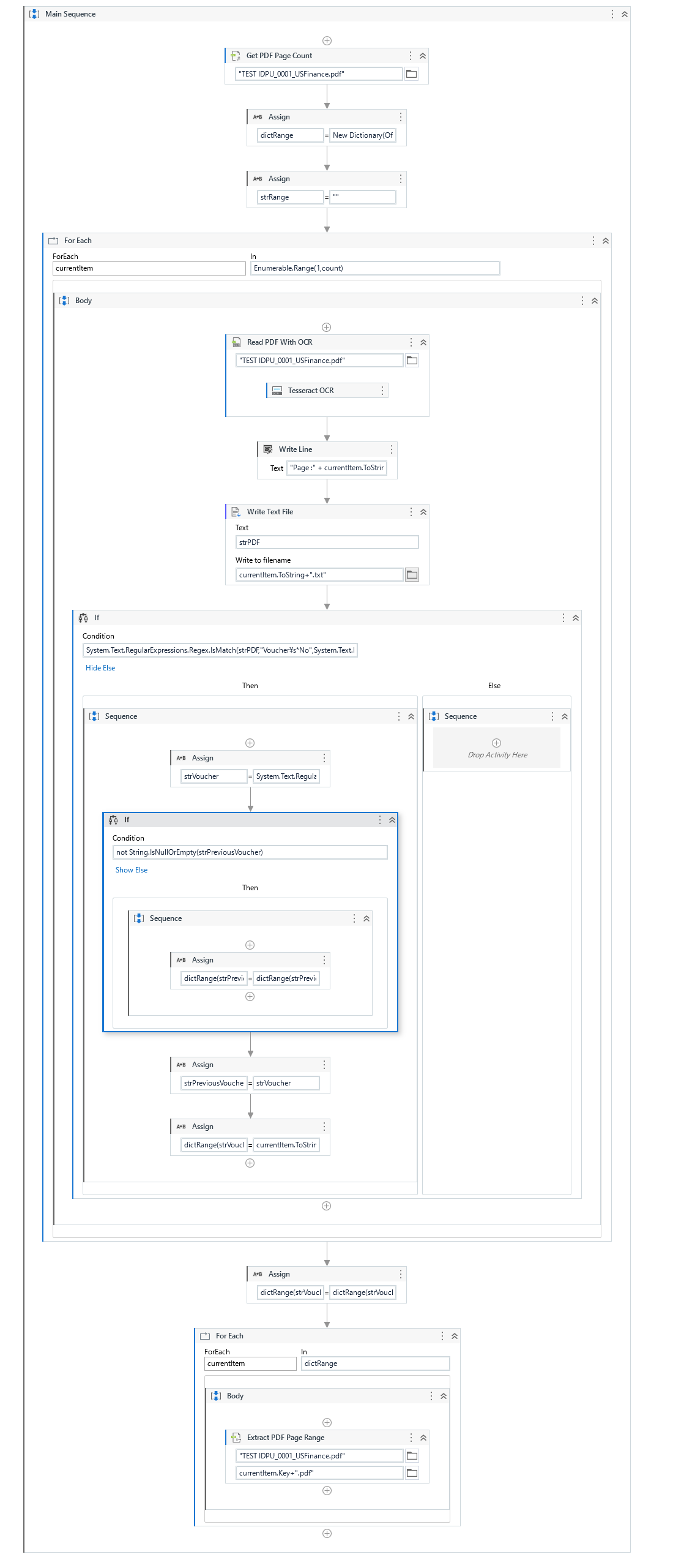
Yes, we can use ReadPdfWithOCR. However, as OCR is not 100% accuracy, there might be incorrect characters. In fact, the following will extract pdf pages which you expect but there are some problem because OCR doesn’t get “Voucher No” correctly. For now, can you try the following sample? (It takes 6 or 7 min. in my environment)