Hi
PFA
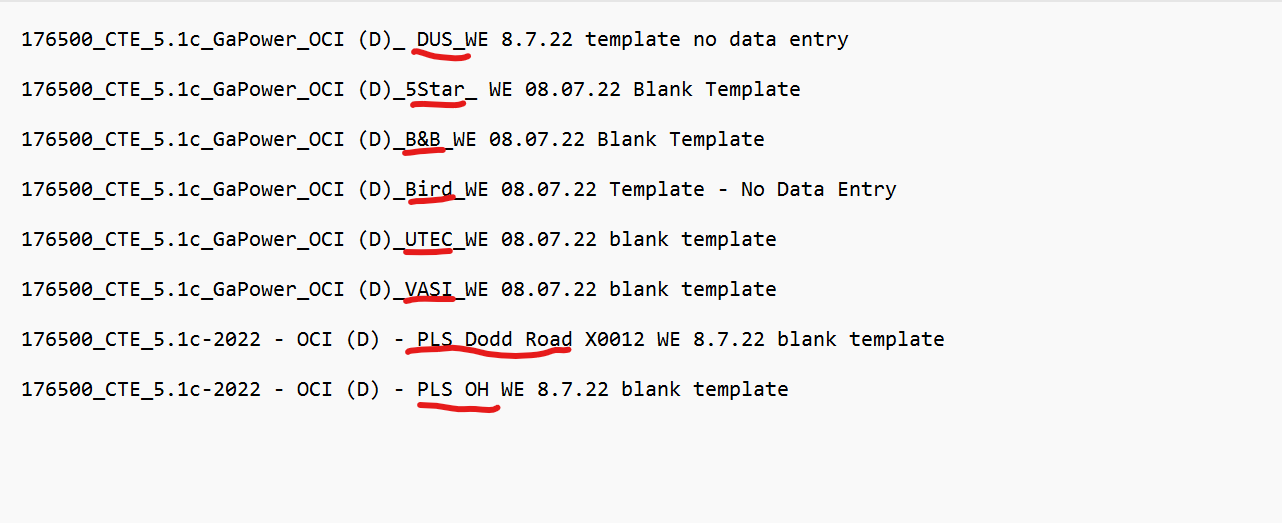
I need to get the red marked names from the file , i tried sub string & split it is not working
Can anyone help me out on this , I would appreciate
Thanks in advance
Hi
PFA
I need to get the red marked names from the file , i tried sub string & split it is not working
Can anyone help me out on this , I would appreciate
Thanks in advance
HI @rsr.chandu ,
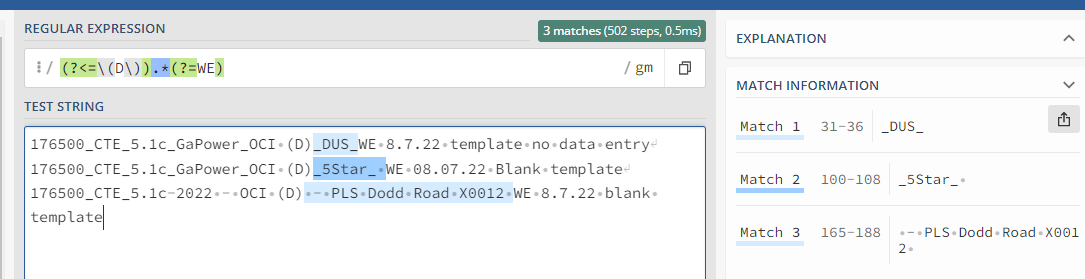
Could you Check with the below Regex Expression :
(?<=\(D\)).*(?=WE)
Expression :
Regex.Matches(dataText,"(?<=\(D\)).*(?=WE)").Cast(Of Match).Select(Function(x)x.value).ToArray

The result however is not an accurate one, But let us know more conditions on how we can remove the extra characters which are not required. Do we only have numbers and letters as the value ? If so we could include all the special characters as a removal condition.
If you could provide us separately the Output from the data, we could maybe analyse on the restrictions to be used to capture the specific data.
Yes, Need only the text special characters are not required
For a more accurate confirmation, Could you provide the Exact/Correct Outputs from the resulted Output in the Debug Panel showed (How the output would look after the Removal of Special Characters).
If you could list down the Output values that need to be extracted, separately in a text file, it would be more helpful for us to be clear on the removal of special characters.
PFA ,

I need the data in this format
Hi @rsr.chandu
say your string is in str then use
System.Text.RegularExpressions.Regex.Replace(str.Split(“OCI (D)”,2,Stringsplitoptions.None)(1).Split(“WE”,2,Stringsplitoptions.None)(0), “[^a-z A-Z 0-9]”, “”)
cheers
We do observe that X0012 is not included as the Output value. Could you maybe let us know what is the reason and how did you identify it as to be removed. If we could make a rule from this observation what would it be ?
Initially, we could see that the data lies in between (D) and WE. The regex provided does the extraction based on this rule. Similarly we would need to identify why some part of the data is excluded and what could be the reason when looked from the Business Team/Client’s perspective.
checked with our team it is not mandatory, to hold that word
but the rest all important
Hi @rsr.chandu
please try this System.Text.RegularExpressions.Regex.Replace(str.Split(“OCI (D)”,2,Stringsplitoptions.None)(1).Split(“WE”,2,Stringsplitoptions.None)(0), “[^a-z A-Z 0-9]”, “”)
cheers