Could you provide us with a Sample PDF document we can work on or Test our approach with it ?
Also, The Input from Text file has N and Y mentioned but it is not seen in the PDF Table as provided in the image. Are these characters appearing only after Reading the PDF as text ? or is it an Entirely different PDF ?
We would need to get a confirmation on the Pattern of the data in the PDF, so that we can suggest/provide you with a concrete solution.
Not completely sure if the method provided below would be appropriate as we still do not know the complete pattern of info of the PDF data. But you could try with the following :
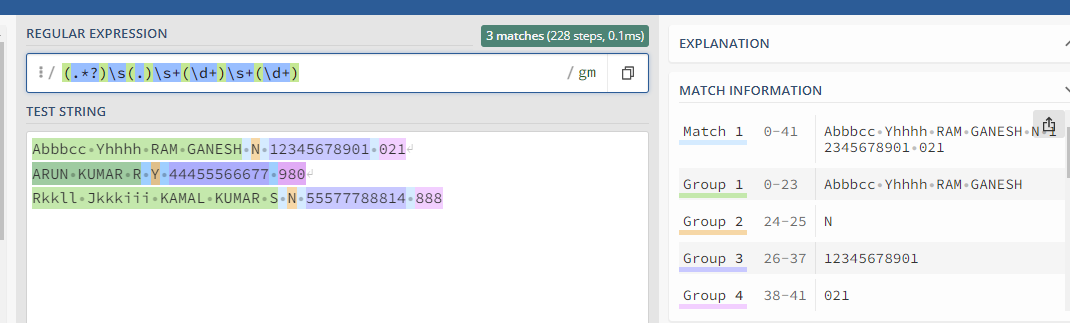
Using Regex we could get the Data separated as required :
We could then populate these data into a Datatable.
Check the workflow below and let us know if it satisfies the requirement for other samples of your pdf documents as well. Regex_Table_Extraction.xaml (9.1 KB)
I have used a text file to read the input data as provided above in your post.
Is the solution provided by me above not satisfying your required output ?
Could you let us know if Text file / PDF is the input or Excel file is the input ? To avoid confusions, you could send the Input data and the Expected Output Data again.
Does that mean while reading the table some unnecessary values are appending and you need to split the text to get the required data? Is this correct or your requirement is something different?