I want to visit multiple pages everyday to automatically download product images. The thing is the number of images varies depending on each product. For example,
Any idea on how to automatically download all the images of each product?
Plus, if you have an idea of actually how to download images in an easier way than right clicking and using “save as” feature, please give me some hints. Thank you so much.
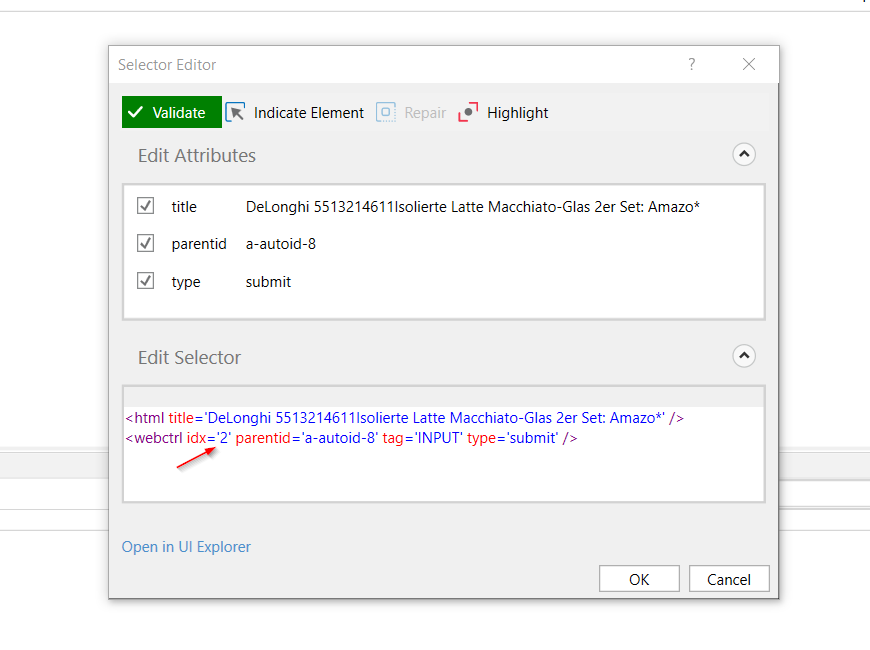
It’s not so complicated but it requieres a little bit of knowleage about selectors. As you can see in this screenshot if I press edit in a simple click button it will show me the selector. In the image you can see the index, the first image starts at index 2.
So you will do a while activity and keep incrementing that number and using right click to download. If you’re selector fails it means that it’s because there’s no more images. So once it fails the process should stop or go to the next URL.
See this post if you wish to know about how to enter variables in selectors:
The last part and saving via webrequest was just done for quick prototyping. Maybe a download via url, navigate to, save as … is more preferable, but it is up to you which procedure you want to use and to work out on production quality level (syncronizing on download progress, exception handling etc)
@ppr
Thank you for your insight. I checked your xaml file but it was a bit intimidating to modify it. So based on your approach, I analyzed the source myself and found this.
I am trying to get all the class elements starting with “image item itemNo*” and hopefully download the img sources inside them. Do you think it is feasible? It seems very complicated to me. Please help me write some JS codes to achieve this.
@Daun
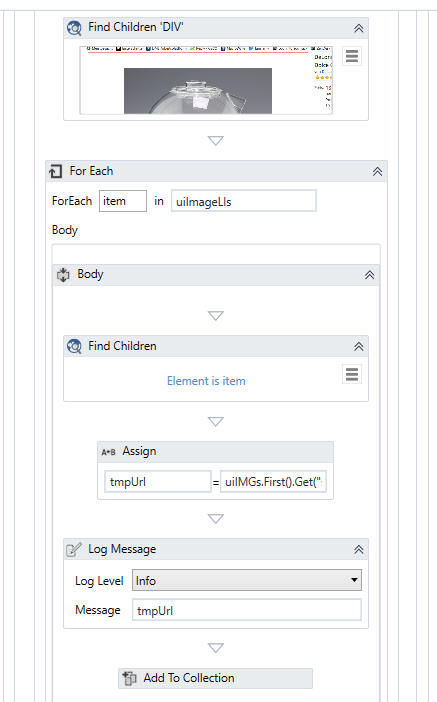
I am not sure if got your question in all. However run the demo xaml and you will see that all pictures are downloaded.
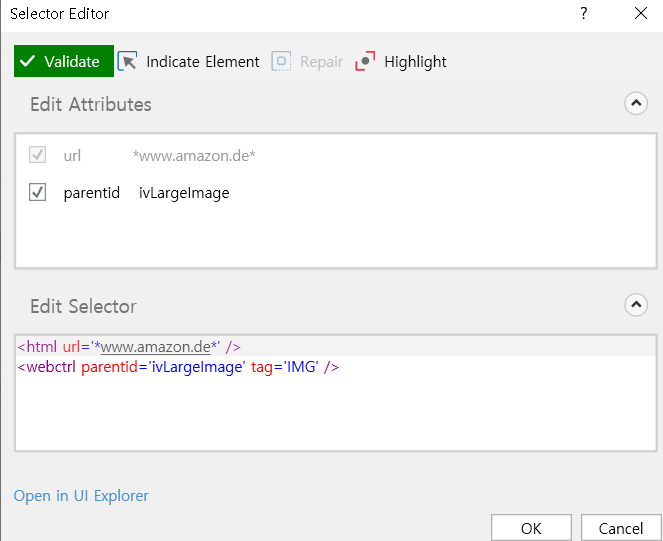
In the demo xaml you will see that the selector was been shortened and is using a wildcard: "<webctrl parentid='main-image-container' tag='LI' class='image item itemNo*' />"
so its retrieving all items and is not confused on the count info.
For this it was more important to have done the hover actions, otherwise only for 1 img the info were available.
A little bit more down, an additional find children is retrieving the img elements. So this part is already available in the demo
In case of I did you misunderstand your question, please help me and eleaborate more on this. Thanks
@Daun
there are pros and cons for attach browser, but i suggest to use it in the current stage of development.
allows you to centralized the Parent selectors
helps to bounce code with others crossspaning different browsers (i cannot use chrome for example, but can help you with prototypes)
will play later a role when you synchronize the bot on the web page (e.g. page is loaded, do waitings…)
about the save image. According to your question I did prototyped setup the download via url with the help of webrequests. It seems to me that you are using the uipath activity save image. But this activity is implemented for the datatype uipath.core.image and is not supporting the url (in the way you tried, I did the same on load image and it failled). The validation comes from that an image is expected, but a url is provided.
@ppr
Where should I put the local path and file name for downloading in the last part?
When I checked the source, it seems that there are img sources readily available without hovering the thumbnail when I unfolded in the source, (though they were in grey color), does the part of the source in grey color mean that it is not available? Can’t we just get the urls without hovering each one of them? (I am sorry for my ignorance)
What does the “invoke method” in the last part do?
@Daun
the invoke code part is retrieving the image data by url via a webrequest
the invoke method is calling the save method from the retrieved image
here you can configure the path to where the image should be saved:
open the parameters panel
configure the path as by your requirements or reimplement it, by passing it by a variable
When I checked the source, it seems that there are img sources readily available without hovering the thumbnail when I unfolded in the source, (though they were in grey color), does the part of the source in grey color mean that it is not available? Can’t we just get the urls without hovering each one of them? (I am sorry for my ignorance)
what counts is the result. In my analysis after loading the page only image data for the first image were available. It is not recommended to hover the icons and then checking the html code.
I do recommend following: setup the flow at your end, test it, afterwards you can optimize and retest. So once all is done then you can check what is needed, eg, by commenting out the hovering action part