Hi Team,I am using ML for Document understanding for some invoices, when we extract data from invoices we are getting the decimal points in an amount in place of comma 6,00,015 amount change and it will be 6.00015, please let me know how we can we deal with that.
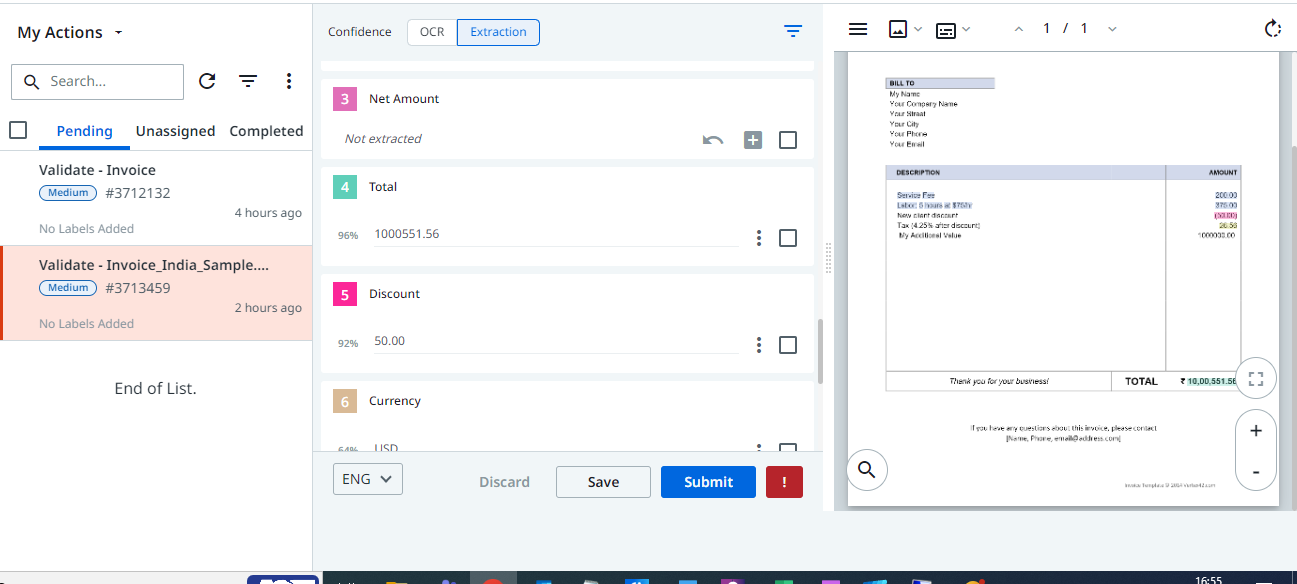
Please check the attached screenshot.
Option 1 - Try with different data types → Int, String, Double
Option 2 - Train the model with more invoices. Uncheck the checkbox corresponding to Net Amount, enter the correct value.
Option 3 - (Could be a temporary solution) For all amounts, use string functions to get rid of the “.” and then convert to Int/ add “,” using string functions. Not sure if you will have decimals in the amount, but if you do, you will have to handle that as well.
What’s the field type you have defined in taxonomy? Have you defined Net amount as “text” or “number”? Please change to text if you have not and test if you are getting 6,00,015.
So, for option #1, what was the output when you tried changing the data type to (1) string, (2) number?
Option 2 → how many additional documents did you train the AI on, specifically the “.” and “,”?
Option 3 → This should have worked. Where did this fail? What did you try?
Also:
What’s the OCR engine you are using? Tried using a different one? (in digitization?
Is this a standard template? If yes, have tried using Form Extractor?
I did try out myself by Deploying the Invoices India ML Package (same version 22.10.0.0) and tested with an Invoices Document which contained an amount that was in the Indian format, However, I was not able to reproduce the issue that you are facing.
Could you check if the Total Amount is getting extracted in the correct manner for the below Invoices PDF (It is a Dummy PDF) : Invoice_India_Sample.pdf (90.6 KB)
Also, Let us know if you are using the Present Validation Station Activity i.e Attended Mode and not the Create Document Validation Action Activity. If you have not yet tried out with the validation through Action Center, Could you let us know after testing with it as well ?
Thanks for your reply,I am still facing the same issue, by using the https://du.uipath.com/ie/invoices_india endpoint.
I am using Create Document Validation Action Activity.
as the amount is a very critical and important term.Please let me know how to deal with this situation?
It does seem that this error in identifying the decimals or commas is indeed happening by the Package itself. It might be due to the fact that the images/documents are of low quality or may be there are noises in the part/section of that area, Hence it might be incorrectly identifying the commas as decimals.
However, this should be fixed in the future Invoice Package releases.