trying to run a loop where i parse through a column and split each row into several rows that i insert below the current row. however, running this from top down means that the loop stops at the original number of rows. could i do this in reverse so row count at the top is unaffected or is there another route i should consider?
We could solve it with an Essential modelling and/LINQ approach.
Assumption: Excel data is readin into a DataTable - dtData
LINQ Approach for above example:
Assign Activitiy
dtResult = dtDataClone
Assign Activity
dtResult =
(From d in dtData.AsEnumerable
From s in d("Items").toString.Split(","c)
Let ra = new Object(){d("ID"), s.Trim()}
Select r = dtResult.Rows.Add(ra)).CopyToDataTable
The LINQ form above decomposed to essential modelling would look like this:
Assign Activitiy
dtResult = dtDataClone
for each row Activity| row in dtData
for each Activity| item in row(“Items”).toString.Split(","c)
Add DataRow Activity:
ArrayRow: new Object(){row(“Name”, item.Trim}, DataTable: dtResult
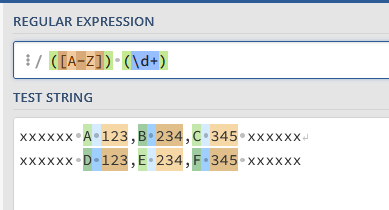
thanks Peter for the very comprehensive solution breakdown. this is almost there, i just have to work in some regex instead of splitting by a delimiter. so it’d be something like this (x is junk text):
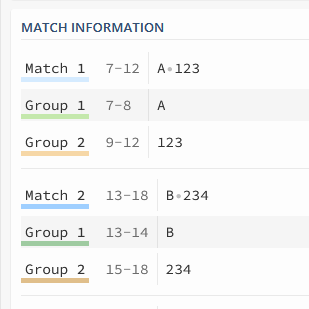
Based on your inputs a regex could look like this:
with refering to Groups:
And above suggestion just need a small adaption
Assign Activitiy
dtResult = dtDataClone
Assign Activity
dtResult =
(From d in dtData.AsEnumerable
Let mts = System.Text.RegularExpressions.Regex.Matches(d("Items").toString, "([A-Z]) (\d+)")
From m in mts.Cast(Of Match)
Let ra = new Object(){d("ID"), m.Groups(1).Value, m.Groups(2).Value }
Select r = dtResult.Rows.Add(ra)).CopyToDataTable