I am new in UiPath. Recently after some video study and communication learning I start to use UiPath to do data extract. This is pdf file with several Invoice number with Invoice amount in different page. Now I face several problems as listed:
After using “Get PDF Page Count” I try to use for each loop to extract every matched “Invoice Number” and “Invoice Amount”. However the result keep providing me with the 1st “Invoice Number” and 1st “Invoice Amount”. How can I get the rest data?
Continue with for each loop, the result keep providing me many times with same “Invoice Number” and “Invoice Amount”. What should I do at this moment? To Split the PDF and read one by one and then later combine together or there is one way that I could read every “Invoice Number” and “Invoice Amount” from the command?
Hello Nguyen:
Sorry I may not provide to you with the file since it contains sensitive information but I can state more detail accordingly.
What this invoice be look like?
This is a PDF invoice that contains invoice no, Material Numbers and Invoice Amount listed. When a new Invoice no occurs, it would move to a new PDF page with new Material numbers and new Invoice Amount.
PDF information format is the same. The only difference is the number of material numbers. With more material numbers the pages will lead to 2 or 3 pages with same Invoice no and finally get only one Invoice Amount for one Invoice no.
Hope this will give you more insight in the PDF sheet.
Hello Yoichi:
Yes, it works. Thank you very much for this part.
But for the data extraction from the pdf. What would be your suggestion upon using repeat activity?
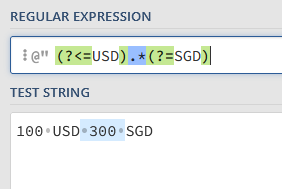
E.g: For Invoice Amount this would be one line data that I will only look for characters between “USD” and “SGD”. I should use assign or regex to get the result? Since the final goal is to read every Invoice No and Invoice Amount from one pdf file. Then after read this page many times I do test for the assign, the result is not so good so I raised this following question.