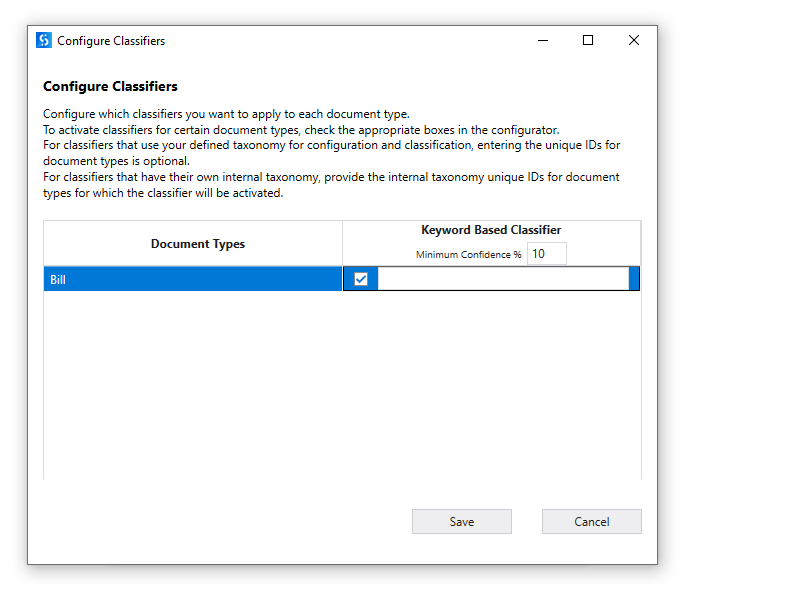
In the check box field you will map the internal taxonomy name to the given document type if applicable…for example if you are using machine learning classifier then it would by default have a classifier for recipt and in your taxonomy you might name receipt as bill…so you need to provide the name recipt in the field against the bill line item in the classifier…if the document type is already your own taxonomy document type…for example for a keyword based the document type would be same as what you provide then nothing to provide there can be left blank
It is to define the template structure and how and what fields would be present where…for more details exactly how to and all…see this detailed explanation