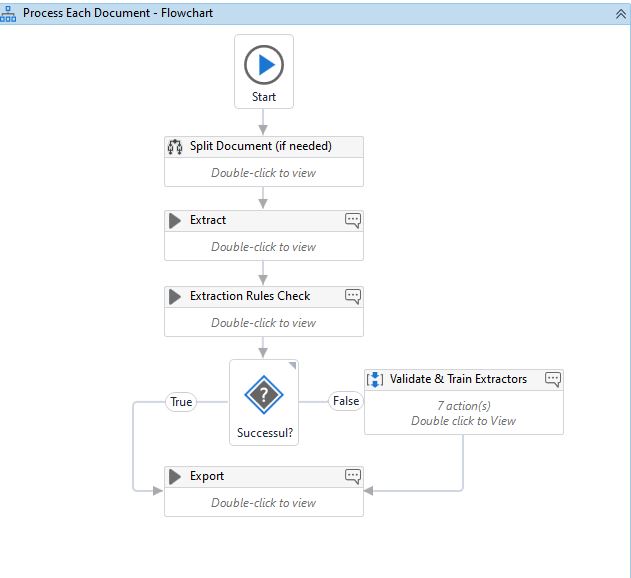
We are very excited to announce the General Availability release of the Studio template for Document Understanding. You can find the Document Understanding Process template on the Official template feed. To get started, simply create a new project in UiPath Studio and select it.
We recommend to carefully read the enclosed User Guide, even if you’re already familiar with the solution. The latest guide is always enclosed when you create a new project and can always be found here.
Below you can find 2 quick overview videos about the Document Understanding Process, and the new Invoice Post Processing workflow. More in-depth videos will come at a later date and posted in this thread as well.
Document Understanding Process Overview:
Invoice Post Processing Overview:
New with 21.10:
New workflows for advanced Business Rule validation for Classification and Extraction.
New workflow for post processing Invoices based on the OOTB (out of the box) model.
Validation Station/Action now only displays the relevant pages instead of the whole file. Removed the PDF splitting functionality.
Support for ML Extractor Trainer to use the auto-retrain feature in AI Center.
New assets / settings in the config file for skipping classification/extraction training.
New assets / settings in the config file to force documents through manual validation (useful in development/UAT especially)
New exception type: DocumentRejectedByUserException. This exception is thrown when a user explicitly rejects a document during validation. When setting the transaction status, a DocumentRejectedByUserException is treated the same way as a BusinessRuleException.
Changes:
Exception handling workflows now receive the Exception as an argument instead of an exception message
Improved logic for loading Orchestrator assets
Improved exception messages
Improved comments and annotations
Improved logging
General Features of the Document Understanding Process:
Queue Integration (Requires Orchestrator 20.10.8 or newer): Default for unattended, and optional for attended mode. Please do note that AutoRetries should not be activated on queues and that the Document Understanding Process was designed with the idea of ONE file per QueueItem!
Try / Catch and Error management: All important activities have a retry mechanisms or Try/Catches over them. If something goes wrong, it will be caught and reported in either ERR_Abortprocess.xaml or ERR_HandleDocumentError.xaml
Business and RPA friendly overview of the project: At a glance you are able to understand what happens where. This adds value by being easier to explain to business users what actually happens in the process, yet at the same time it simplifies the structure for ease of access in case of errors or feature requirements
Ability to use an attended or unattended bot with this process by selecting the correct main.xaml
Classification retraining implemented directly in the workflow: It just works!
ReusableWorkflows folder with 2 implementations for Classification retraining:
Lock/Unlock file – default, already implemented.
Thank you for your interest in Document Understanding! If you have any questions or feedback, please use this thread or open an issue here, in our git repository. If you do want to contribute and create a new branch, please be mindful of the naming conventions in the README.md file.
Hi, was wondering why the pdf splitting functionality was removed. In my case, I’m trying to take a big doc and split it based on document type -ie, classification result. In the summer preview, it looks like this was just in there and I wouldn’t need to do much short of defining my taxonomy and training a classification model. in the new framework, is there another way to accomplish the same effect with minimal customization?
Hi everyone! @radekmoczy - the plan is to have it in 22.4. So far, we are on track.
@supervij - it was removed because the Validation Station/Action now have the option to only display the relevant pages instead of showing the whole document. Removing the splitting also has the added benefit of not having to re-digitize the split file in order to get the new DOM/DocText.
You can simply add this functionality yourself, If your use-case requires the actual splitting of the files. I have encountered this need in one of my implementations, but, overall, this is a very rare situation.
Thanks Alexandru - Great to know that it’s coming back. In my case, all I need to do is split a large doc based on document type. I’m not extracting anything, just classifying and splitting. I’m currently attempting to bring in the split workflow, remove the redigitization step / multiple assigns and added the setting to the config. In theory, we can split the document and the rest of the framework would be none the wiser. Will let you know if this works.
@supervij - No, the splitting functionality is not coming back in future releases. But you can easily implement it using the Extract PDF Page Range activity in the UiPath.PDF.Activities package.
Thanks for the clarification. Agreed…easy enough to bring it in.
This may not be the right forum, but do you know if there are any enhancements to the taxonomy manager and/or the classification validation station? One of the problems I’m dealing with is scrolling up and down…in taxonomy manager, the add document type button is at the top, but the input text box presents at the bottom…when I’m adding lots of document types, I save and then have to scroll all the way up to add the next one. Not sure if there are any alternatives to this (was considering building a bot to update the taxonomy.json file directly.
The classification validation is more difficult, if not error prone, with large documents. Same sort of problem. The document classifier is at the top of a scrolling list of pages. So, if I wanted to manually train the model using the validation station, I would need to scroll down, select a page and then scroll up to classify it, then scroll down to the next page, and so on. The first file I tried has 450 pages and I have about 20 of them. Are there any alternatives to this?
We do have a version for C# as well, it’s in preview right now and can be downloaded from studio directly. There was an issue and for some reason it was hidden. It is fixed now:
Note: The GA version of this will release with the 22.10 release. While it should work, obviously bugs can happen. If you do find ANY issues, please come back, tag me and let us know so we can fix them before the GA release. Thank you!
I need to extract invoices for two different departments. One department requires data such as invoice number, due date, invoice date, and total amount. The other department also needs to retrieve vendor name, vendor address, and items from a table.
What is the best approach to implement this in the framework?