I am trying to extract PDF which has question below that date is mention. I applied anchor base method to extract date from it but it is not working!!

Any help would be much appreciated!
Thanks!
I am trying to extract PDF which has question below that date is mention. I applied anchor base method to extract date from it but it is not working!!
Any help would be much appreciated!
Thanks!
Hi @Joker ,
Is there a Reason that you are using Ui Automation for this Case?
We could read the PDF Data and Perform a Regex Match to get the Desired Result if the PDF is a Digital PDF.
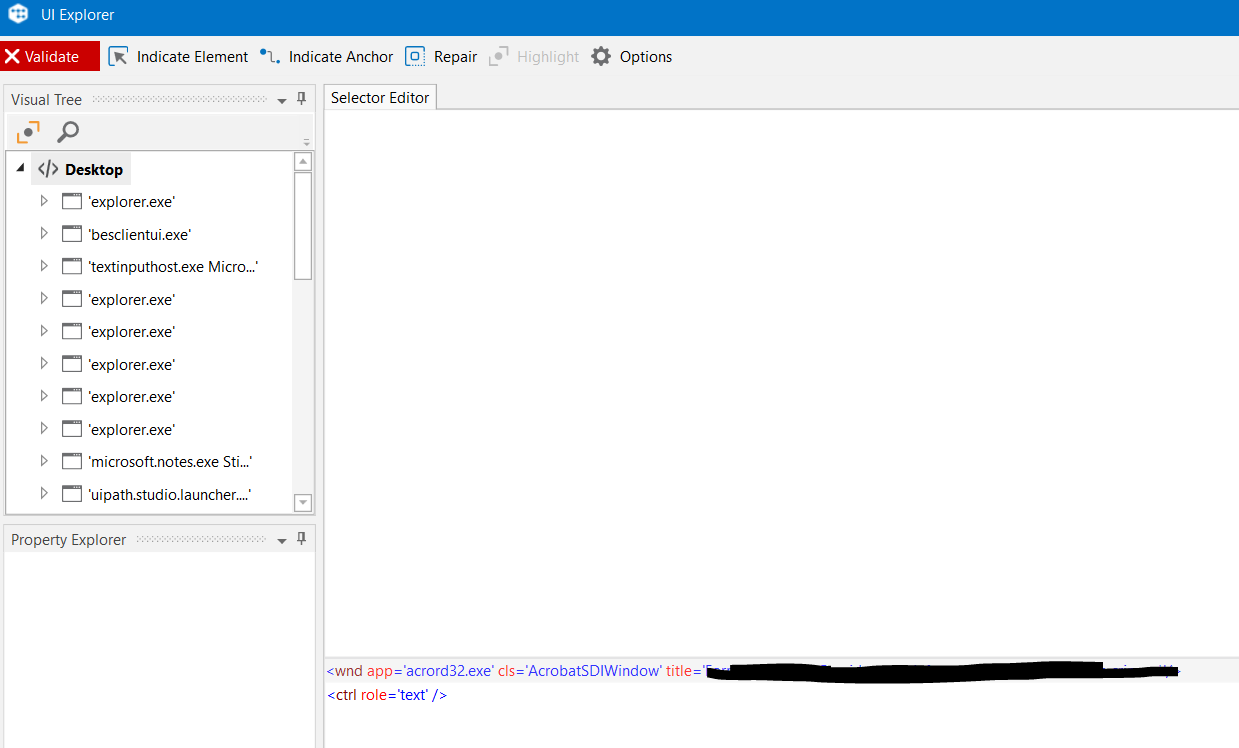
If you still want to Continue on UI Automation, Could you Provide us the Screenshots of the Selector of Date Element in UiExplorer ?
Hi,
Regex isn’t one of my strength so I thought taking another approach. Moreover, there are multiple dates present in the document. However, I am looking for specific date. Is that possible to extract using Regex?
Below is the image of the UI Explorer
This is when selected at first
Thus, I also tried to open UI explorer and re indicate the element and save it.
But then I got the below error
Get Text: The specified combination of selector, filter and scope is not supported.
@Joker UI automation will not be reliable for the pdfs. It is possible to apply regex if the pdf can read to text format
Please check the below workflow on how to convert pdf to text. Share the output in the notpad then we will assist you how to apply regex
PDF.zip (2.0 KB)
Note: For this you need to install UiPath.PDF.activities

@Joker , It does seem that the Selectors cannot be guaranteed for the PDF data.
However, if there always is a possibility of using a Background automation than Foreground/UI we would need to go with the Background automation.
In this case, Reading the PDF data as Text and performing either String/Regex operations to get the desired data.
If you could provide us with the Pdf Data in Text format, we would be able to suggest you with a Regex Pattern that we can use to Extract the Date.
On a First Look Basis of the Input data, we can assume to use the Following Regex Patterns :
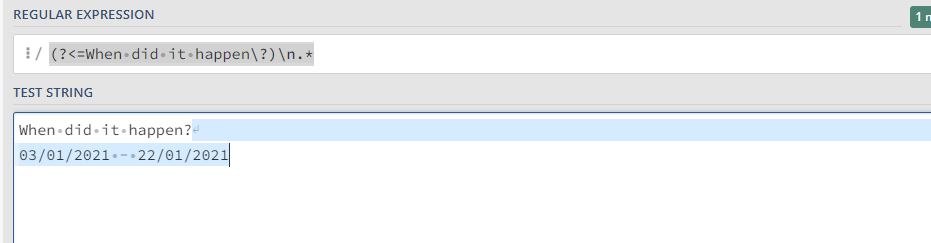
1.
(?<=When did it happen\?)\n.*
Expression to get the Match Value :
System.Text.RegularExpressions.Regex.Match(InputString,"(?<=When did it happen\?)\n.*",RegexOptions.IgnoreCase).Value.ToString.Trim
(?<=When did it happen\?).*

Expression to get the Match Value :
System.Text.RegularExpressions.Regex.Match(InputString,"(?<=When did it happen\?).*",RegexOptions.IgnoreCase).Value.ToString.Trim
Let us know if either of the Expression doesn’t work and Provide us with Text Data, so we could provide you with an Accurate regex pattern.
Hi, thank you suggestion. I have read the PDF into text. But I put a hard stop when it came to Regex. However, I think I will try it now with Regex.
That is informative. It gave me a great insight. So basically, for accurate PDF extraction we should go with Regex. Is there any site which can help in fetching correct regex which can be simply applied to UI Path?
Thanks a lot for the Regex expression. I would surely go over Regex course to get an complete understanding.
I appreciate a lot for your help.
Let me try and if there’s any issue with it I will surely ask for your help.
Cheers!
Very Informative posts have already been provided in the forum, like the below :
The Extraction of Data depends on the Input data, so it differs for different data.
I tried (?<=When did it happen\?).* expression. It is printing empty in the console
@Joker , We would require to inspect your Pdf text data. If you could provide us the Text data, We can give you the correct regex pattern.
@Joker If you are not able to give us the pdf text data then you can go through the below video and find out the solution.
|ReGex builder UiPath|IEnumerator")
@supermanPunch @shreyash_shirbhate
I would have provided without a doubt however, it has sensitive data that restricts me to share it. The PDF is behaving weird as for some text it is showing and for some it is not. Not sure why?
It is a Digital PDF right? @Joker
Not sure, how do I check it?
Hello @Joker,
You should try using regex or Data Scraping ![]()
It is not handwritten right? @Joker Which mean it is digital.
ohh! no it is not handwritten. It is digital
Already tried regex. Will data scraping resolve that issue?
@Joker If the Data was not extracted using Read PDF Text, it can also be that the PDF is a Scanned PDF, meaning there are images in it.
We would require you to confirm on the PDF types present, as we cannot proceed with Normal PDF Activities if that is the case.