I want copy the text of “tax alerts” in webpage format and paste it somewhere else (into a form and an empty Word document) with its format. If I manually copy and paste it, the format will be included.
I know that you can copy text for example by screen scraping and by using the NATIVE method, but it doesn’t include much of its format like headers in bold and the fontsize.
A way to do copy the text into a form is by copying the html code, since the form I want to paste the text also supports html input. Then I will have to remove anyhting that is not content, such as the menu, the header of the page etc, but this is quite complex.
Does anyone knows if there is an easier way to copy the text in its original format?
It might be easier than you think (depends on how the target application handles different tags).
See attached example: HtmlCopyTest.xaml (6.9 KB)
It finds the section element (similar to how you’d find it for ScreenScraping), gets it’s innerHtml, sets it to clipboard and sends ctrl+v to Notepad (redirect it to your app of course).
It might require some tweaking for your use case, f.e. removing script tags etc., but should give at least a way to move forward.
Thank you for your help! It works like a charm. I had to cut some extra things out, but it wasn’t bad after all. It is good to see you can do so much in UiPath itself.
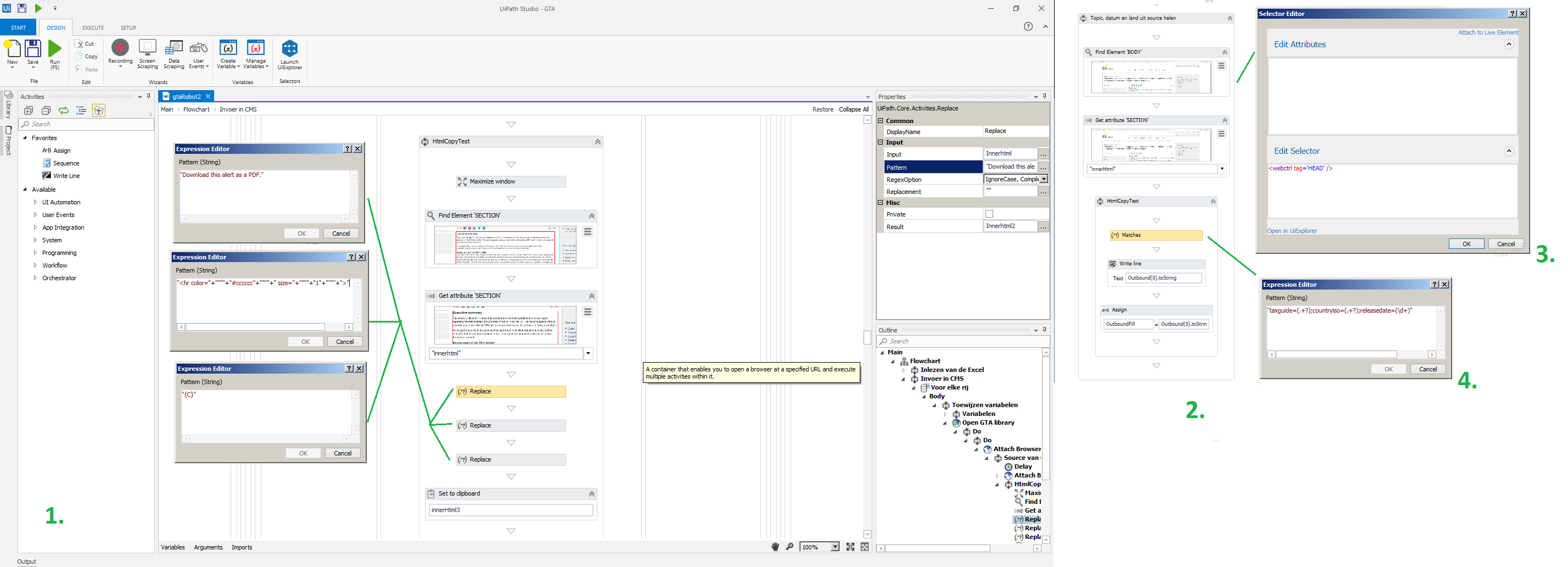
First of all, I used the example mr. Kniola made.
I had to cut some things out, for example a bar/line that always shows up at the button, the sentence that says : “Download … PDF”, and some random C’s that showed up after copying. I still do not know why they were added, but at least I got rid of it. You can see those at 1.
Secondly, I wanted to get some data out of the webpage’s header, because it contains the date, the topic and the language of the Tax Alerts (which are the articles on the webpage I need.).
Of course, you cannot “grab” the head of the page, because it is not a physical part of the webpage.
So I had to adjust the selector manually. I first selected the body, and than replaced “body” with “head”, so it would grab the invisible header. You can see the selector at 3.
Since there is only one sentence that has the information I need, I used a “match activity” (4) to get rid of all the unnecessary html code. I used regular expressions to do so, as I did to when I had to replace text in 1.
So to summarize my story , I wanted to get some parts of the source: the contents of the webpage and some information that is in the header, and then I had to do some adjustments by using replaces and matches so only the html code I needed was left.
Thank you for your help and I hope my explanation was clear.
Yes! Sorry that I am replying so late, but here it is!
I used the solution of beesheep!
Is the activity “Get attribute”, and then I selected “Section”. The selecter I used can be found after 2.
This actually already excluded most of the unneeded html.
This matches the EYG score, which is a identifier for each EY Global Tax Alert.
This is the regex pattern which extracts the EYG score from the html
The EY Libary is very inconsistent, and for some Tax Alerts, there is no “<p Class=”(…)score(…)" in before the score itself. In that case, the robot searches for the pattern: “EYG no. “NUMBER"Gbl”
A disadvantage is that is possible that the robot will then extract the wrong EYG number, since it is possible that the author refers to another Tax Alert by its EYG number, so initially it will look for the “<p Class=”(…)score(…)” in front of the EYG score, while the second option underneath “Try Catch” (5) is a last resort option.
It was fairly easy and I would like to thank beesheep for his solution!
If you have any questions, feel free to ask!