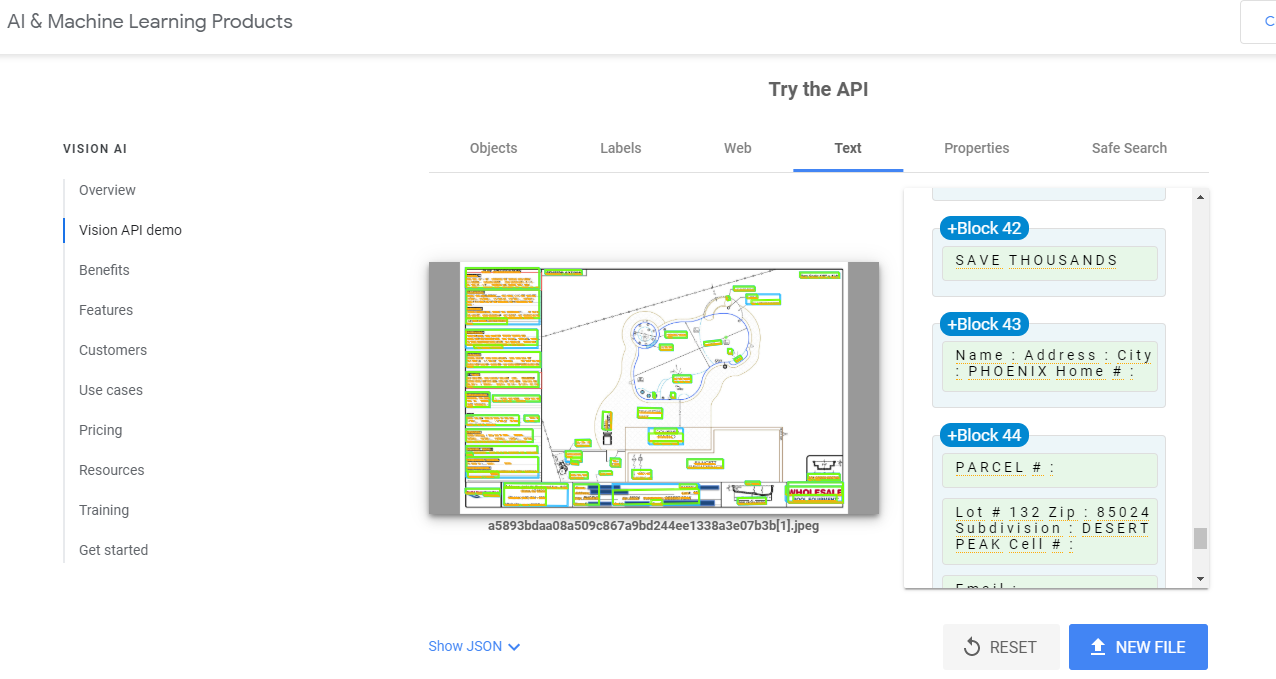
The areas with a Red box around them is what I need. They are very small and OCR seems to be having a lot of trouble. These are the things I have tried
Extract just Text ( does not work because the CAD file is flattened before it is sent out so this is considered an IMAGE
Extract text with OCR trying multiple OCR engines Google, Microsoft.
Changing Scale with OCR scan so it can get make the small text a little bigger
Changing my DEFAULT app for opening PDFs I typically do my measuring on BLUEBEAM but since this is a very advanced software I did not want to wait for the load time each time it opened a new PDF so I tried just opening PDFs with Google and then using a scrape function ( this did not work either )
I most recently tried to change my PDF viewer to Adobe thinking it might help but it seems to not of made much of a difference.
If I could pull the text only, I am not to bad with Regex now and I wouldn’t mind using a matching activity but I can’t even get there.
After everything I have tried, I am almost certain this will have to be where a human does the leg work and types in these fields so the bot can continue but that really loses touch with the fact this is automation.
I look forward to hearing from anyone who thinks they have a good answer for this. If you need me to send you a sample version of my PDF for testing on your side let me know.
Woah dont be sorry my friend that looks like a great scrape :0 your making me feel hope for this part of the project once again
I’m going to read this article now does it tell me how I get that API? These files are stores locally on my Dropbox sync folder so are in a path and i have to tell it what app to open with. Should I be using Google chrome I assume with using Google api? Gonna read this now may help solve this.
Thanks so much will 100% be looking into this it aswell looks super cost effective for my needs.
Can you let me know just curious before I go start playing in there.
Does it count a text unit as per character or per word? As well I cannot see what it is outputting for the text is it looking super accurate for the perimeter for example?
I’m not quite sure how to read that code in all honesty that does not look like anything within uipath I assume I will see more of it when getting started with vision AI thanks again!!
Pricing Guide says that Bills are charged per image, and for PDF’s Files, A page is treated separately. A unit is a Featured applied to your image, in your case Text Detection is your unit and Google will charge you for every unit applied to your images.
You can create a program in C# and call from your robot, or create Python Script. No matter language, robot can deal with that (that’s the easiest part )
In all honestly I do not know any coding language
regex atm is the best I got but I believe I have it down. Looking at your code i think i could change certain parts of it to pertain to my needs ( need the general field off that pdf and the decking info, and as well the main customer area I need there address info ) sounds to me like that would be considered as 3 seperate units which I would set up on Google’s side.
Is C# best used with Google vision AI as I will start learning how to read and write it today if so.