We’re happy to report on our latest work for the Document Understanding product encompassing updates in the area of both classification & extraction ![]()
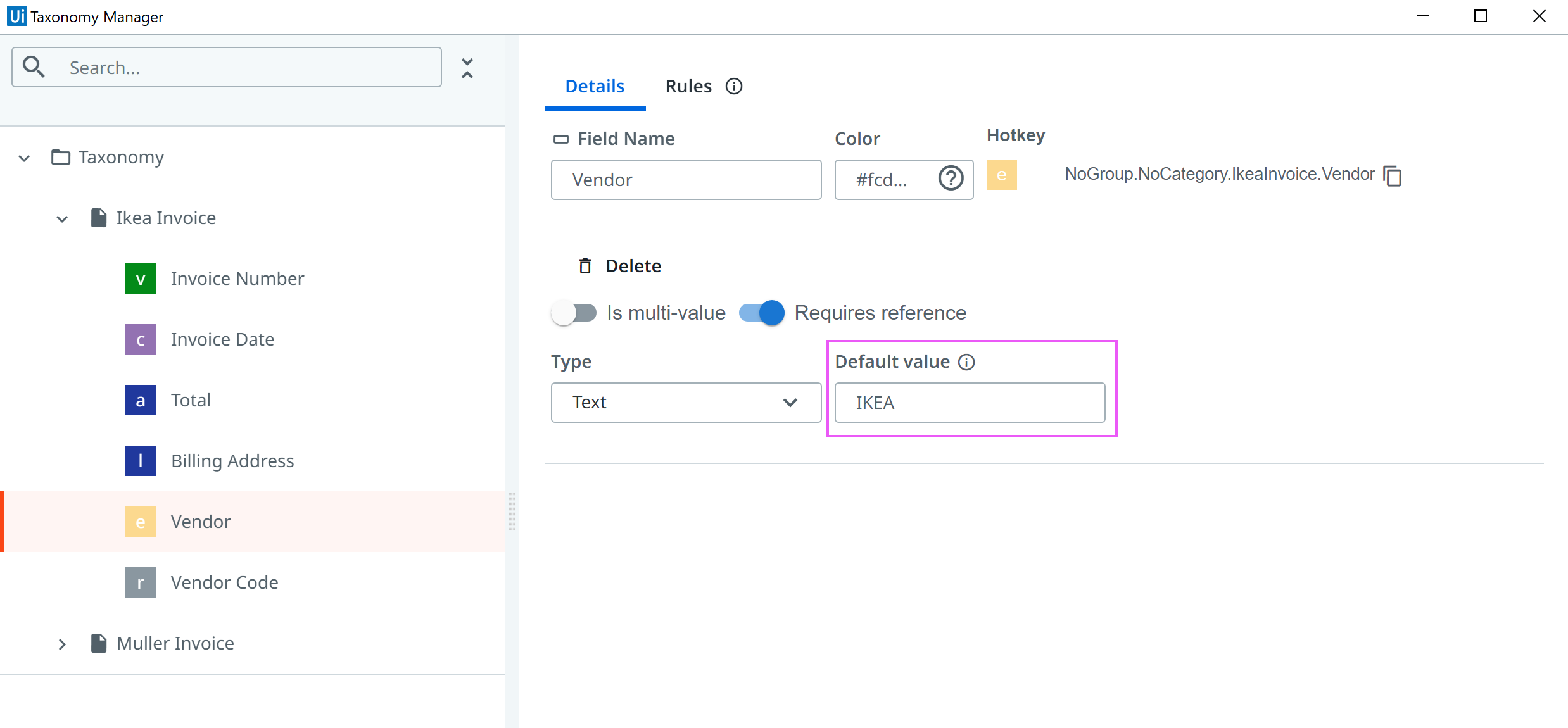
Definition of a default value for a Field ![]()
Have you ever wished for a fallback value to be populated in the Extraction Result, when a field could not be extracted? Have you ever wondered “Why manually inputting the same value, if it comes empty in documents?” - wonder no more! ![]() With the latest release, one is able to provide a “Default value” for fields, which will be populated in the Extraction Result in case no other value for the field has been found in the document. In this sense, one does not need to repeatedly select “False” when no checkbox is checked or provide a default value to not leave an input empty, because nothing else was extracted - it just works!
With the latest release, one is able to provide a “Default value” for fields, which will be populated in the Extraction Result in case no other value for the field has been found in the document. In this sense, one does not need to repeatedly select “False” when no checkbox is checked or provide a default value to not leave an input empty, because nothing else was extracted - it just works!
OCR updates ![]()
We have migrated the Omnipage OCR to .Net5 portable, so that you can now use it within Linux robots ![]()
Improved Classification Experience using the Intelligent Keyword Classifier ![]()
We are happy to report that we have improved the splitting algorithm: now the algorithm can take page numbers into consideration and does a better job at identifying where documents start and end. For example, it looks for “Page 1” or “3/3” or “Page 3 out of 3” to identify the starting and ending of a document, resulting in more accurate splitting.
And in case you do not want to use the splitting algorithm provided with the Intelligent Keyword Classifier, you know have the option to disable it. Until now, the algorithm would split documents even if if splitting wasn’t necessary. Now, the splitting feature can be disabled using a checkbox option.
Finally, we have also improved the splitting algorithm to better split documents of the same type within a file - shall you not notice our improvements, please reach out - we’re happy to help out!
Reporting of the Text Type in the Extraction Result ![]()
![]()
Text can come in documents either as handwritten or printed, checkboxes or other elements. With the latest release, the Extraction Result also makes this information available for you to consume, enabling the use case in which handwritten documents are sent for validation or checkboxes are further collected & processed.