The goal of this document is to provide an overview on how to fine-tune a Machine Learning model in UiPath AI Center. Fine-tuning is a method of training in which the previously validated documents are used to improve the model’s performance.
Before updating the model, the performance of the fine-tuned version should be thoroughly assessed.
Fine-tune steps:
- Download the fine-tune dataset from the AI Center.
It is best practice to store your fine-tune dataset directly in AI Center. You can download the full dataset from the dataset tab like this:
After downloading the dataset, you can store it locally. We will use it later on in the fine-tuning process.
- Navigate to the Document Understanding Manager and open the Document Type.
In the Document Understanding suite, navigate to the Document Types tab. Here you will find the Document Type created during the initial model training. Be sure to reuse this one, as it was created specifically for your document type including the correct Taxonomy.
Clicking on the Document Type will bring you to the Document Manager:
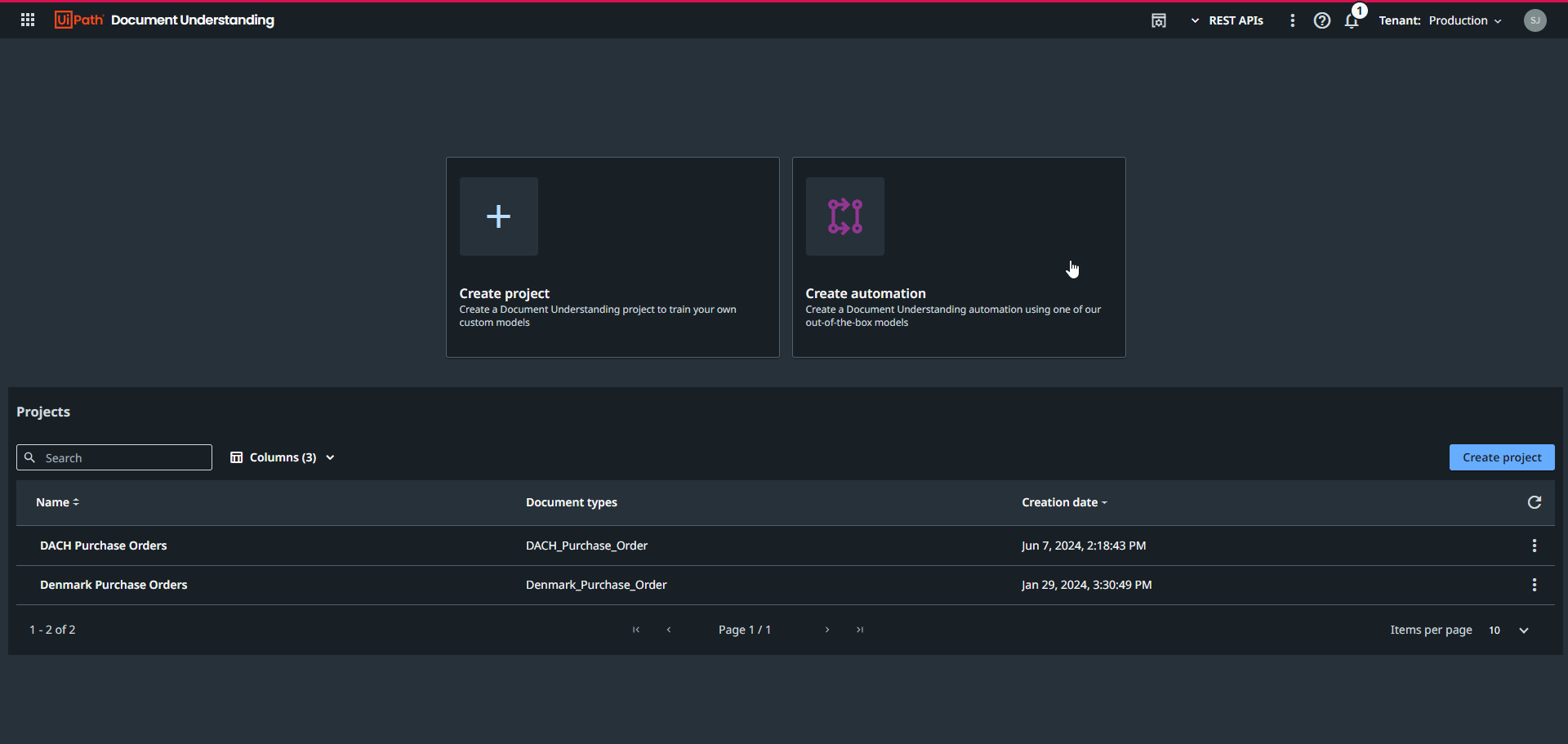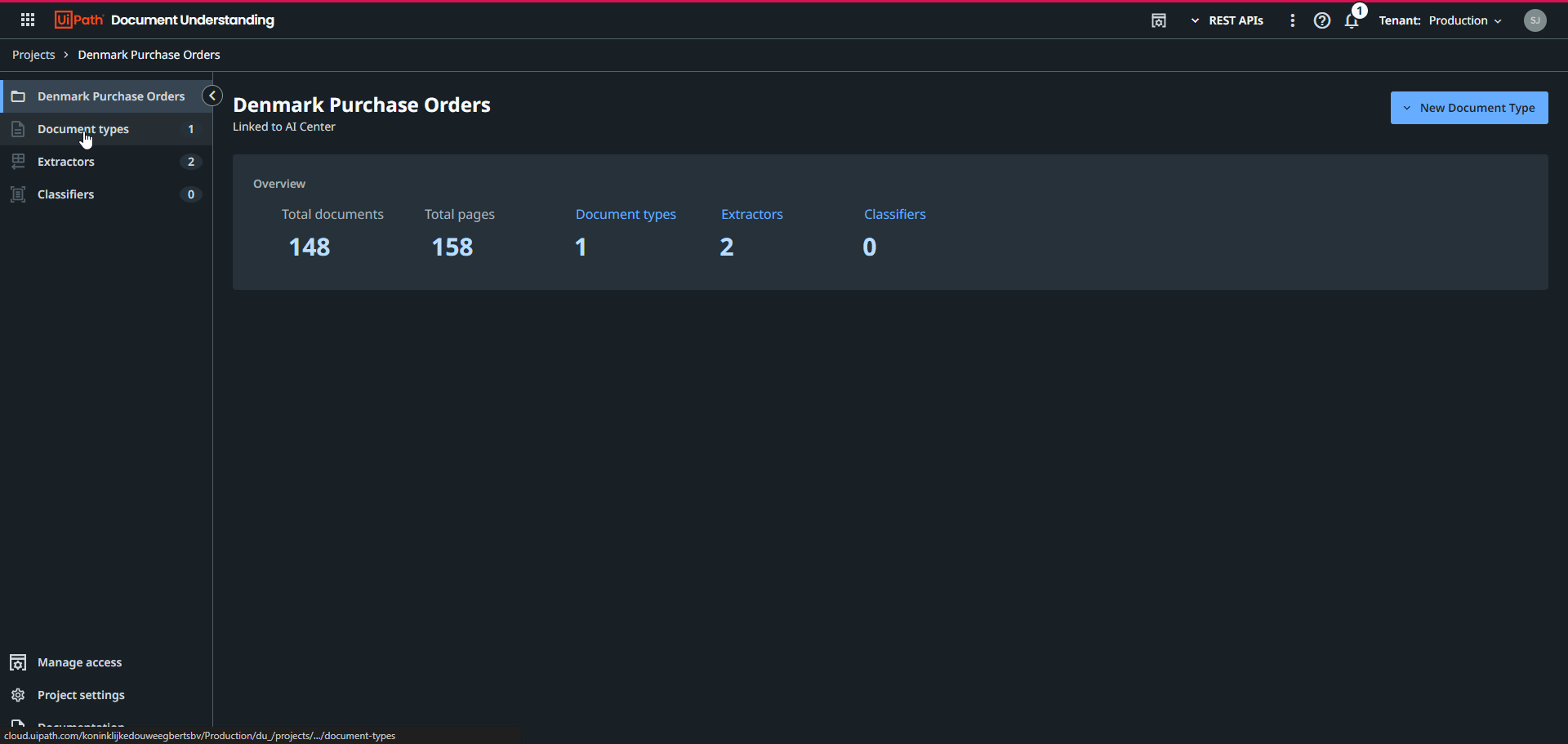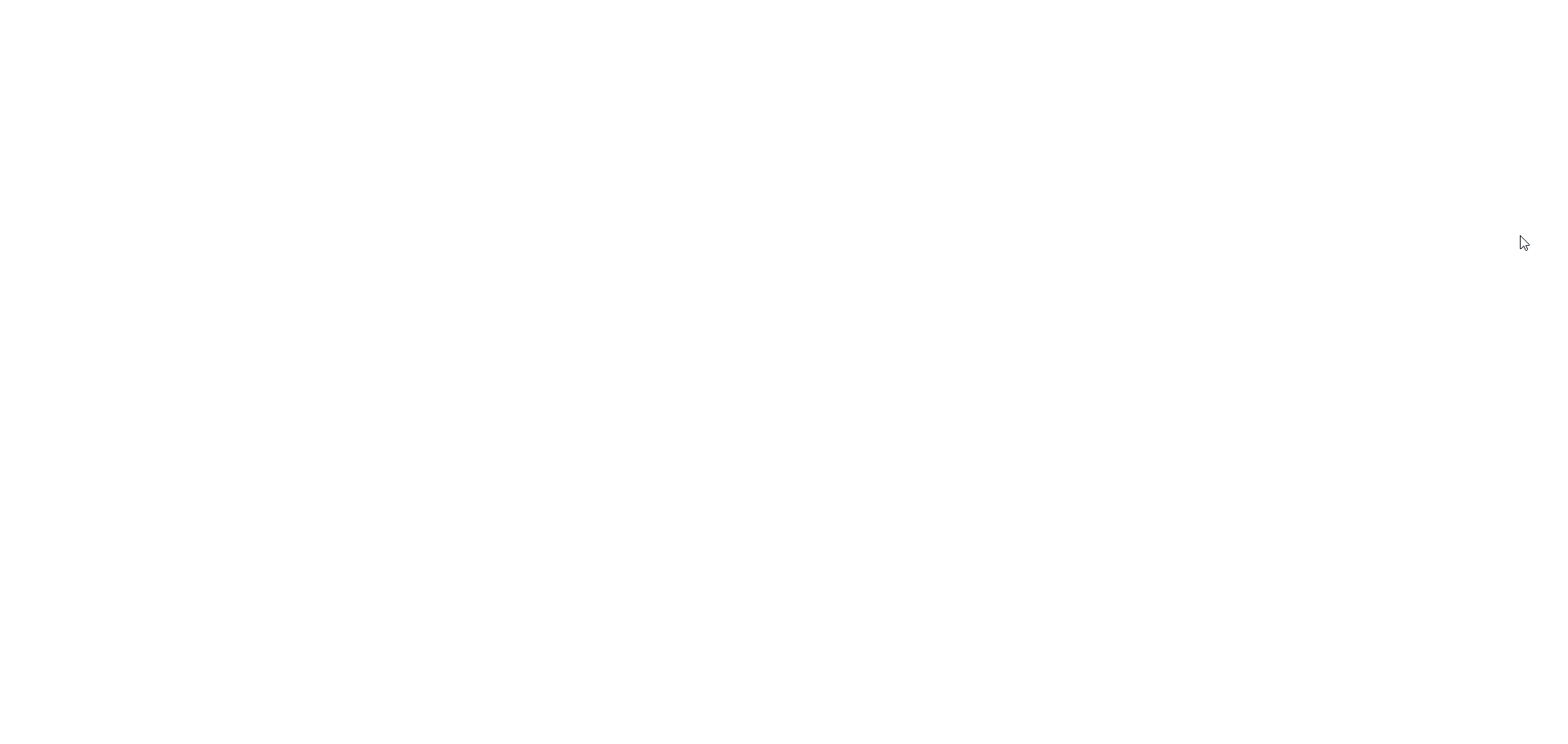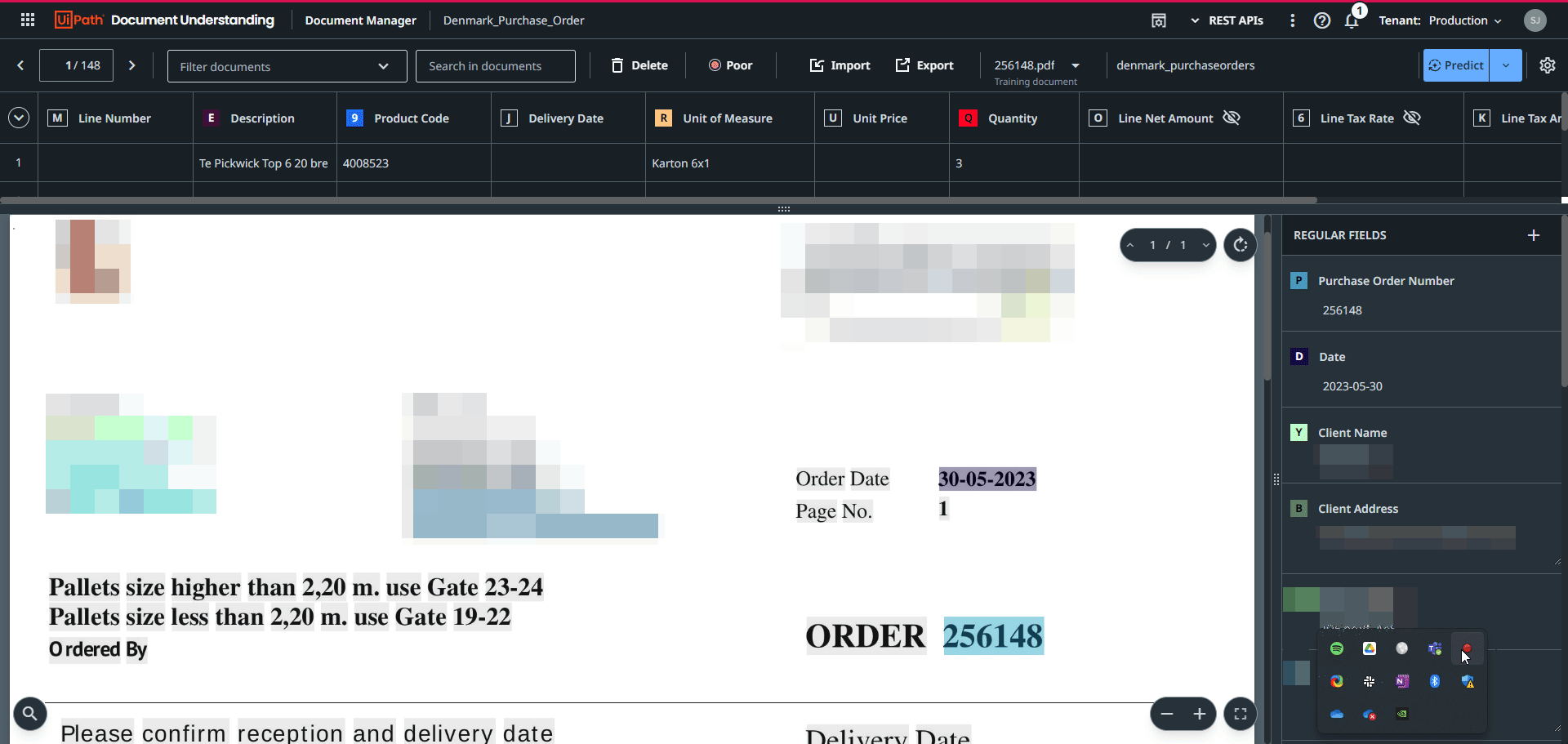
- Grab your fine-tune dataset and upload it into the Document Manager.
In the Document Understanding Manager, click the Import button and select the fine-tune dataset that you stored locally. This will add the fine-tune documents to the initial training dataset:

Since the metadata of the fine-tune dataset already contains labels, no additional labeling actions are required here.
- Export the dataset from the Document Manager to the AI Center.
Now that we have supplemented the initial training set with the fine-tune dataset, we can export the dataset back to the AI center. We can do this directly from the Document Manager by clicking the Export button:

After clicking the Export to AI Center button, the export will start & you can keep track of the progress in the Logs tab. The dataset will be exported to the AI Center where we can use it to create a new train pipeline.
The export dataset is created in a folder named after the Document Type specified in the Document Understanding suite:

Note that exporting may take a few minutes depending on the size of your dataset.
- Create a Train Pipeline on the newly created dataset.
With the new dataset in the AI Center, including the fine-tune data, a new version can be created using a Train Pipeline. You can do this by navigating to the Pipelines tab and clicking the Create new button. Since we are creating a new version of our ML model based on the validated documents, we will execute a Train Pipeline Run.
Since our fine-tune export also contains the documents on which the model was trained initially, it is important here that we select the base version of the Package!!
Training on a minor version other than the base would skew our model towards the initial documents.
You might want to enable GPU to speeds up the fine-tuning process.
- Modify current deployment
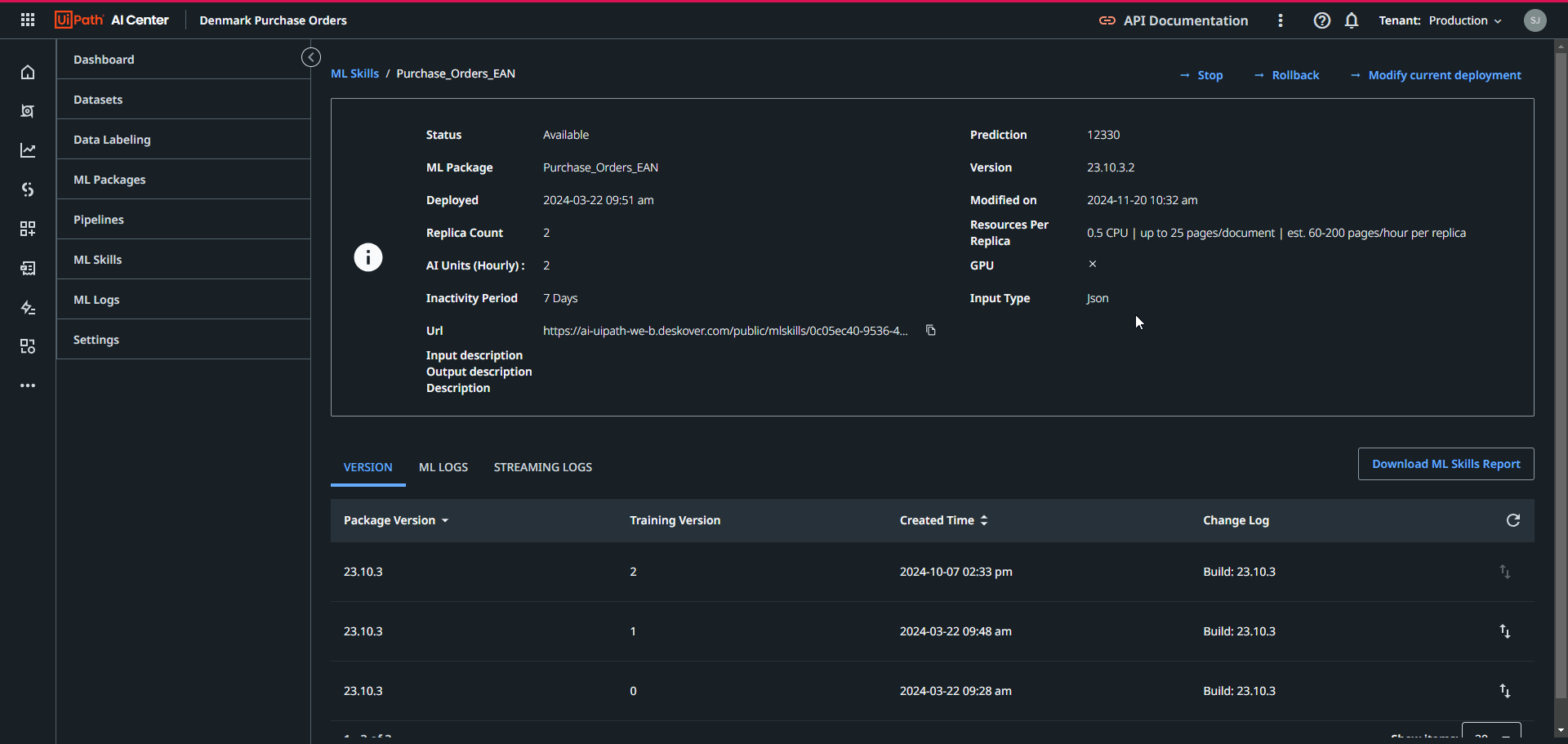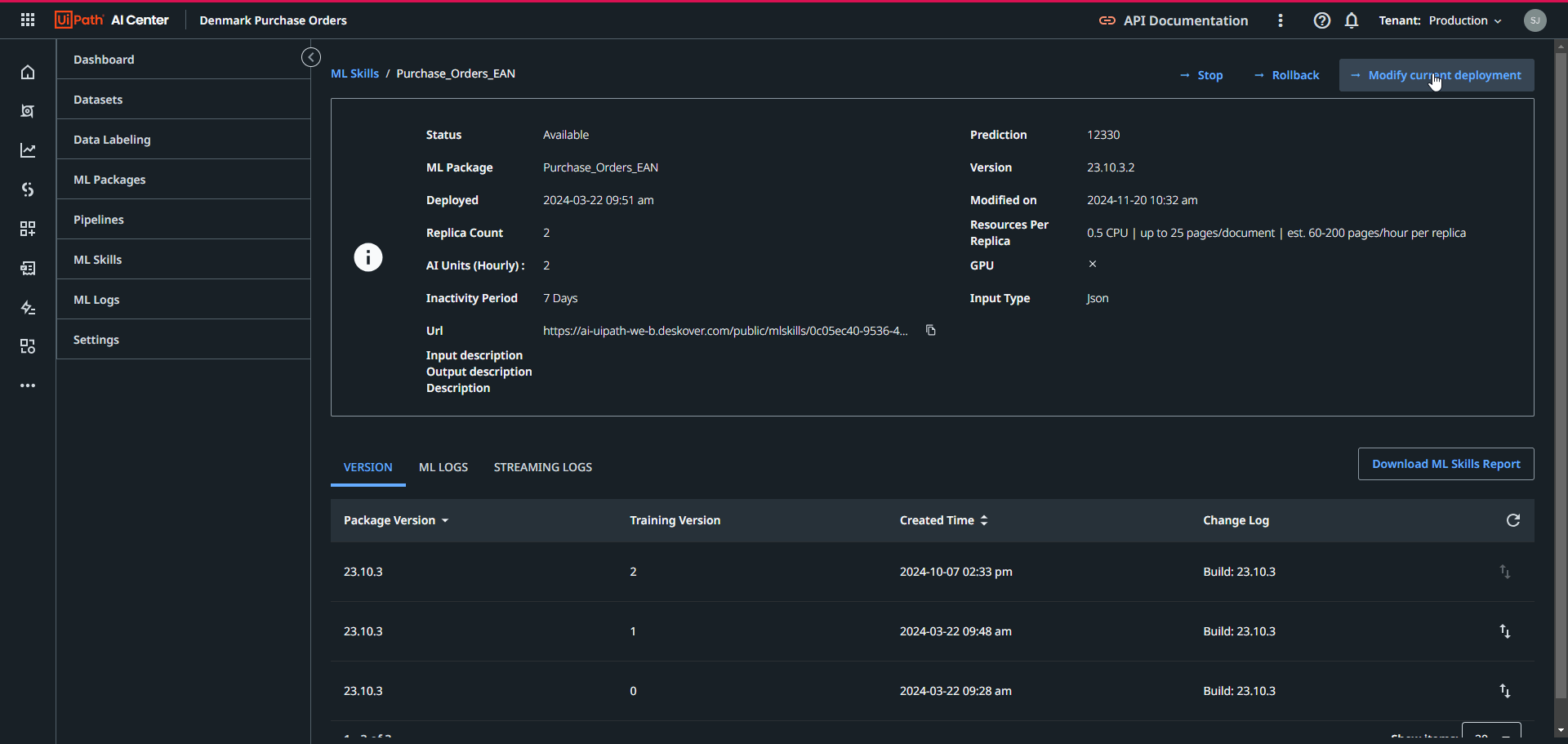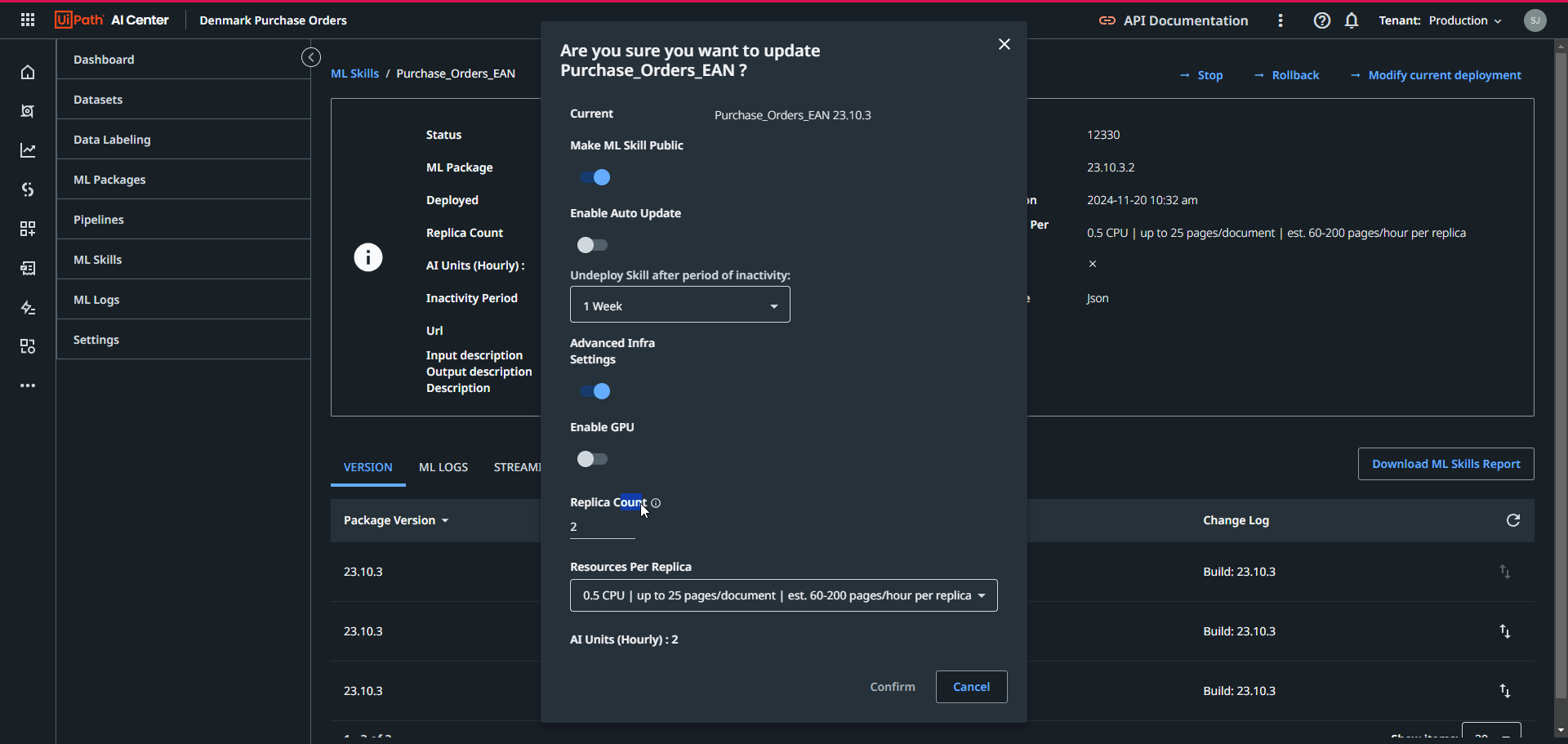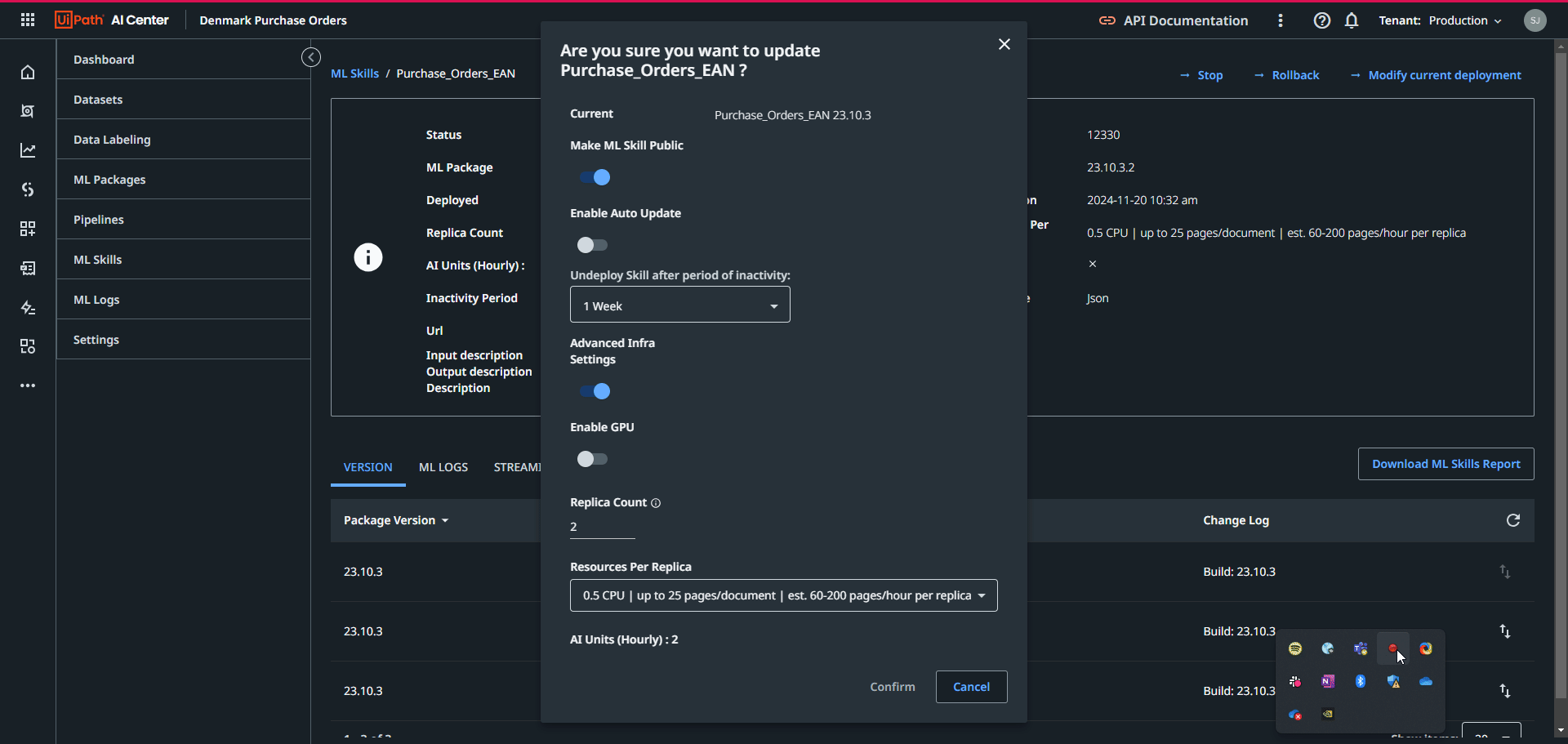
After finalizing the pipeline run, a new version of the ML Skill will be available in the ML Skill tab in the AI Center. If satisfied with the new version’s evaluation scores, you can modify the version here to the newly created one:
That’s it, Now you have fine-tuned your model!