I am having some trouble with a variable OCR application.
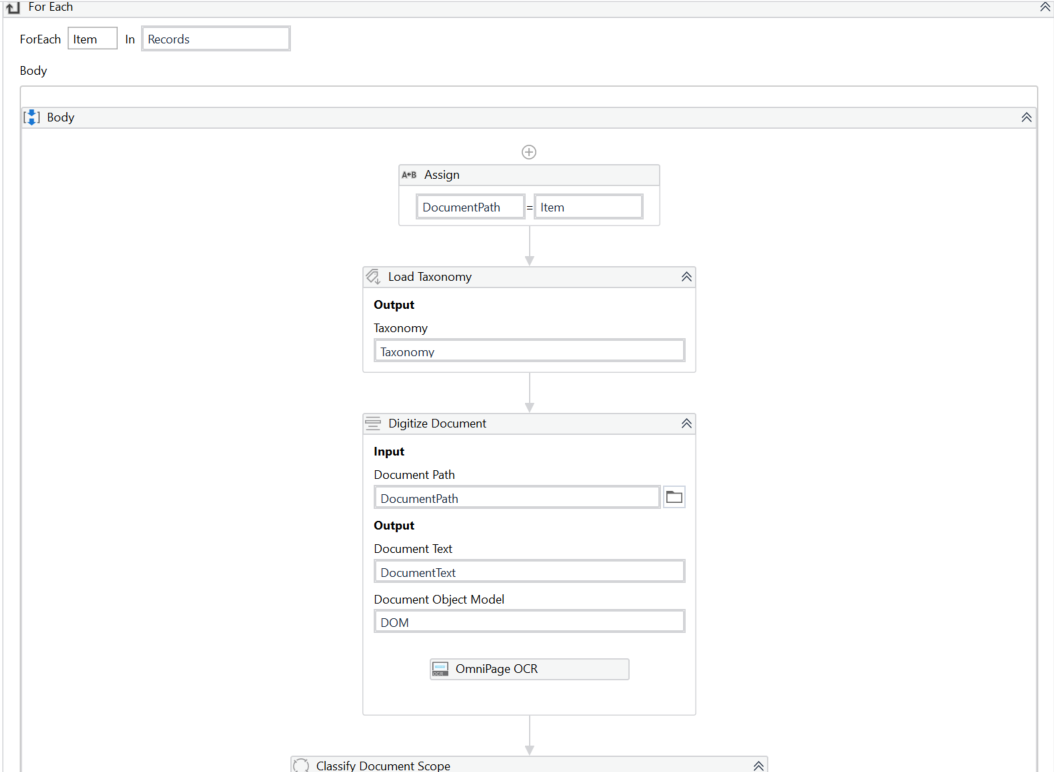
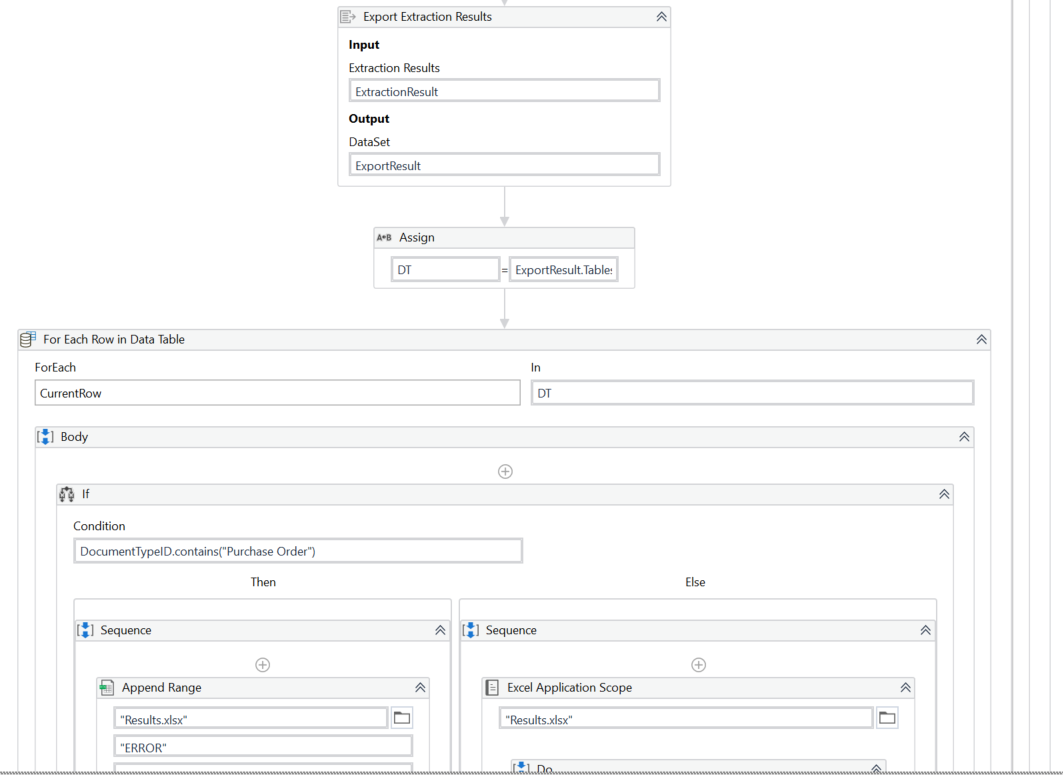
Scope: I have an RPA created that will extract data from a standard PDF file. This is a purchase order document. The document will have a variable number of lines in the sales records area of the PDF file.
Problem: The RPA that I have created works properly if there is only one sales record on the purchase order. If there are other orders I cannot seem to extract the data
Question: What is the best method to scrape each of the sales records that appear in my PO file?
Is there a way to have the RPA identify how many sales records there are and then scrape 1-3 lines?
What is the extractor being using in Data extraction scope?
Please use ML extractor for extracting PO related infos. Please check the link below for more info
Thank you for your suggestion. Currently I am using Form Extractor. I am going to try the machine learning extraction. I will report back with my results.