I have trained a ML document understanding model using my data (invoices). Now according to this video Training UiPath Document Understanding ML Models - Data Manager - Part 2 | RPA - YouTube he says to increase the accuracy either train on a large set of documents or train the same model multiple times (as he does in the video where he trained the same model multiple times and has different version of the same model i.e. 11.0, 11.1, 11.2 and so on!). My question is:
1.) Is it advisable to train the same model multiple times?
2.) If yes then how can I do it as I only have 10 documents trained. What minor version should I choose when setting up the training pipeline? Should it be 0 or the latest version?
It is recommended to add some more documents into your Data Manager and label them as you only have 10 documents, which will not help to improve the accuracy instead add more documents to the same Data Label and train them.
Please choose always the latest version for the Minor version for the pipeline run.
Make sure Data Labelling is done properly to achieve more accurate results.
If you want to train the latest Model created you can go with the latest version or if you want to train the starting model created you can go with the 0 version.
You can use any of the version deleting on the requirement, as I use the latest Model to train each time to get more accurate results.
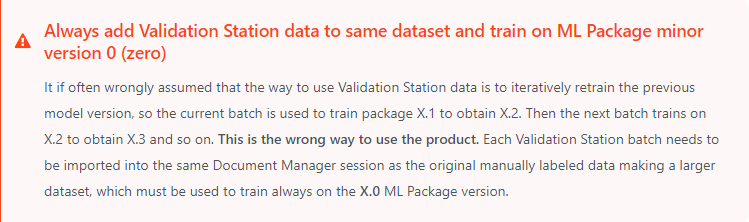
@suraj.setty I am confused. Let’s say I trained once and upgraded from 11.0(base version which only contains the default data) to 11.1 (base version data + custom data). Now if I want to retrain the same model, if I choose the minor version as 1 would it consider only the the custom data or also the default data?
Generalizing the question, what is the difference between choosing minor version as 0 and 1?
Your understanding is Correct once you train the base version say 11.0(base version which only contains the default data) to 11.1 (base version data + custom data).
Since the updated version 11.1 contains both the data , you can train that Version to improve the Model.
Lets say if you train 11.0 again which only contains the base model , there will be again discrepancy with the data.
@ushu What is the logic behind this? As mentioned in my previous comment if I train initially, the version will change from 11.0(base version which contains only the base data) to 11.1 (upgraded version which contains base data+custom_data). Now if I want to retrain on some new docs or on the same docs, I should select 11.1 as it contains more data and would result in better results! but according to the link you provided, it says other wise. Can you point out where am I wrong in my logic?
@suraj.setty Any help/guidance would be appreciated!