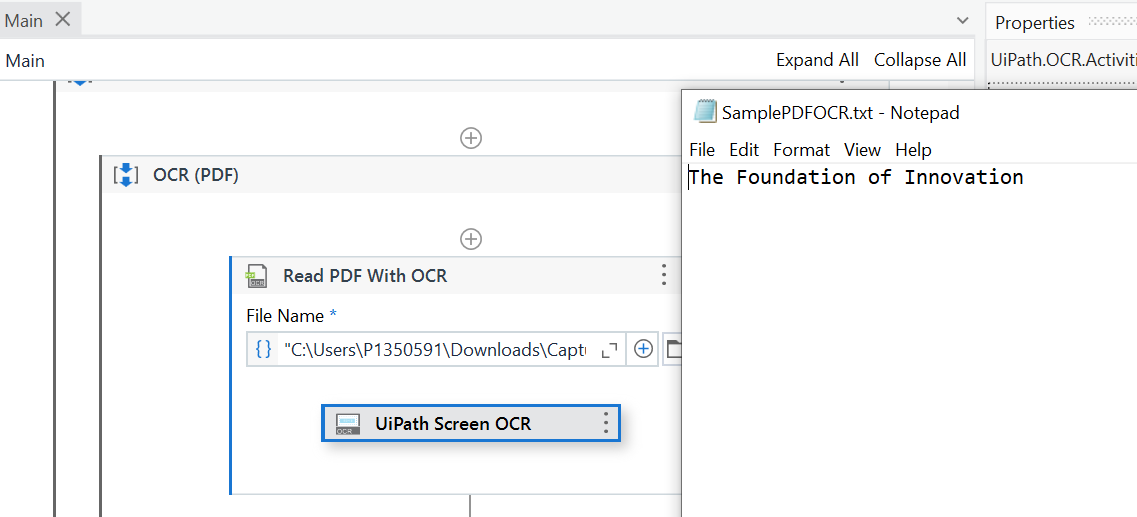
May I know how to get a particular text in a PDF file using Read PDF With OCR activity? For example, I just want to extract the text “The Foundation of Innovation” from the attached PDF file. I do not need to extract the entire pdf file.
Kindly see attached files for the PDF file and the .xaml file. Thank you.
The activity Read PDF with OCR would be extracting all the text from PDF.
Later you would need to perform certain String operations to extract the data.
In your example I can say that TM is the breaker.
Lets say all the data is stored after reading from OCR is in PDFData.
please try with different OCR engines available in the studio.
For better results use the scaling property. and find the perfect value for it by experimenting.