Hi,
My process is,
Search employee number in pdf.
if found, extract the page as separate pdf.
Pdf is larger in size (200-500mb) and pages count (30000 to 60000 pages.)
Read pdf text is taking too much time to read (more than 1 hour or so)
I tried opening the pdf and search the employee num (by ctrl+F). That also taking so much time (more than 1 hour for 60000 pages).
any easy way to extract particular page in the large pdf if keyword found within few mins?
Hi @vigneshnkv,
Is employee number always going to be on same page no?
And within what range of pages, this is found? Limiting the range to those number of pages to be read should be helpful here.
Also, is this pdf a native pdf or scanned images are also there in it?
Regards
Sonali
No. each page has different employee number. So it can be any employee number or in any page.
No range limit, it can be at any page.
pdf is digital/ native (readable), not scanned.
Hi @vigneshnkv
well i would suggest to read it page by page and within a loop
inside it iterate through each pages of pdf and check whether the pdf page contains that string
if yes break out of loop and save that page number as well
I think comparing with regarding all pages in pdf at once , this will save your time
I think so
try this way around
Regards,
Nived N
I have tried this method also.
Each page taking 8 seconds to check.
if so, approx It will take 80-90 hours to check one pdf which has 40000 pages 
Hi @vigneshnkv,
Considering the file size and your requirement, To be honest, I don’t think there can be any other quick solution to this.
I think its fine if it is taking an hour or so.
Some processes are bound to run for longer times basis their nature.
Regards
Sonali
1 Like
Thanks,
as of now, I am opening the pdf and searching the data (as we do manually) by BOT.
Start process - Open target file
Advanced Search - Search the keyword
wait until result come
once match found, get the page number and extract it
It is some what good in time consuming. if you have any ideas/ thoughts on this method. kindly add that.
Hi @vigneshnkv,
Thank you for sharing details.
Could you try below:
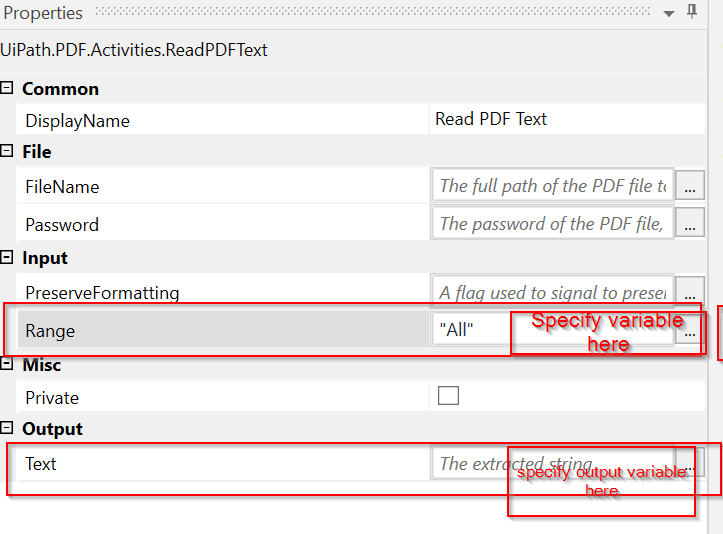
- Loop through each page separately.
- Read pdf text(that page only… under Range specify the variable/counter that you are using to loop through all pages)… If pdf also contain images, use Read pdf with OCR instead.
- Save its output
- Include a logic to search through employee numbers you want to search within that resulted text.
- If found, extract the page you are currently on, else move to next page.
Regards
Sonali
Read pdf text: page by page loop:
Each page taking 8 seconds to check.
if so, approx It will take 80-90 hours to check one pdf which has 40000 pages
@vigneshnkv,
Each page taking 8 seconds to check manually(by opening pdf and searching), right?
Regards
Sonali
No.
Read pdf text activity taking 8 seconds per page, if the file is large.
opening pdf and searching is taking 0.07 seconds (70 milliseconds) only. → I am going in this method now
Hi @vigneshnkv,
Good to hear that, I just wanted you to try and make sure how long that route is taking.
So I think, we are back to our point that the approach currently being used is the right way and its bound to take lil long due to huge file size 
Now that your doubts are cleared, I would suggest to mark solution so this topic can then be closed.
Regards
Sonali