Need help in the below scenario. I have gone through all the help topics and could find an exact solution for the scenario.
My scenario is, I need to find the duplicate rows in the main datatable based on the “Subject” column and the keeping the 1st occurrences and other non-duplicates in the main datatable and move all the duplicates to another new datatable.
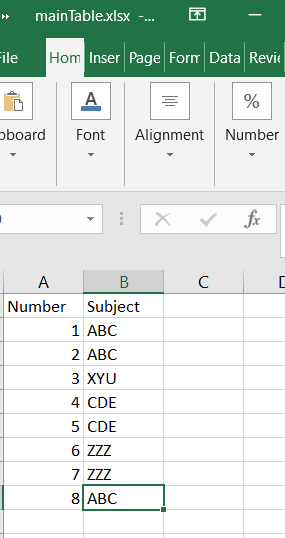
Main Datatable:
New Duplicate Datatable should look like this:
So once we moved the duplicate to the new datatable, the main data table should have the rows as shown below:
Or
In otherwise I need to add a Column “Duplicate” and mark the duplicate rows as “Dup” keeping the first occurrence.
I was just going through your linq, could not get it,
could u please help me understand this?
what is this K? i know d is a alias.
(From d In dtData.AsEnumerable
Group d By k=**d(0).**toString.Trim Into grp=Group ---- could not get it…
Where grp.Count =1 — ???
Select grp.First()).CopyToDatatable
I want to know what this query is doing?
asi too have thing to implement so.
Hi @ppr, Thanks a lot your solution has partially worked. But I am facing one issue with the duplicate datatable. The duplicate datatable contains all the rows which are duplicate in the main datatable.
My main data table:
Currently, after running the program as you provided I am getting like this:
non-duplicate datatable(which is correct as per my requirement):
Duplicate datatable:
My requirement of the duplicate datatable is shown below (which is the rows of the duplicate values after the first occurrence in the main datatable):
For example, in my main datatable AAA is repeating 3 times, so my NON-duplicate datatable should contain only AAA - 1 and my Duplicate datatable should contain AAA - 3 and AAA - 7.
Hope you understand my requirement. Thanks in advance and much appreciated.
For retrieving a List of Duplicates that doesn’t include the first values, you can use the following Linq Query Statement:
(From d In dtData.AsEnumerable
Group d By k=d(0).toString.Trim Into grp=Group
Where grp.Count >1 Select grp.Skip(1).ToList).SelectMany(Function(x) x).ToList
I took cue from @ppr’s brilliant solution. By the way, don’t forget to mark @ppr’s answer as solution.