I m using this synntax to extract First name - System.Text.RegularExpressions.Regex.Split(str,“\n”)(9)
I get index was outside bounds of array @supermanPunch @ppr

@pravin_bindage
because there is nothing like \n present in doc so there is only 1 index and you are trying to get 9th index.
Okay then how can i extract that strings. In write line it shows every string to new line so i think that there are various lines
take a first look and inspect what Word readText is returning:

we got:
\n -marked with #
\r - marked with +
\a BellChar chr(07) - marked with %
as we do not see any # we do see the typical word pattern \r\a

I get this as write line output
Kindly refer to above shared info, which shows details that are not visually captured by panel outputs
check and do see that there is no \n Asci code 10
Also crosschecked by this:


As a first suggestion, could you replace the Word Application Scope with the WordDocument Read Text activity ?as there were unwanted characters when used with Word Application Scope.

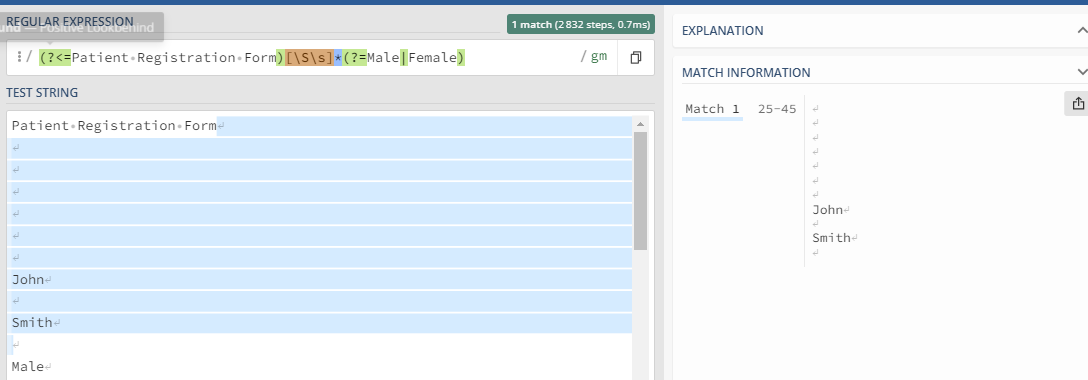
Then using the output text, we should be able to get the First Name value by anchoring between Patient Registration Form and Male|Female like shown below :
Regex :
(?<=Patient Registration Form)[\S\s]*(?=Male|Female)
Expression :
Regex.Replace(Regex.Match(docText,"(?<=Patient Registration Form)[\S\s]*(?=Male|Female)").Value.Trim,"\r?\n"," ")

We also remove the carriage return or NewlIne Characters using Regex.Replace() with pattern \r?\n
1 Like

i got the john as output you can check.
FormWord= System.Text.RegularExpressions.Regex.Split(Text," ")(2)
@pravin_bindage
This topic was automatically closed 3 days after the last reply. New replies are no longer allowed.