Hello i need to create a robot which extract data from a lot of pdf files which are on different languages(around 15) , but with the same structure. The structure is like that ( Section 1 , Section 2 , Section 3…)
I need to take the information from Section 11 to Section 12 it’s around 1 page and half for every pdf.
Section 11 :
Example text… 1 page and half mostly.
Section 12.
Is there a way to make bot to search by keywords for example From Section 11 to Section 12 and also for the other languages i guess i need to add other words which means Section 11 and Section 12.
I need to export this data in TXT file. Is it possible for every pdf which bot scan to extract it in different txt file.
If your pdfs are text pdfs you should use the ‘Read PDF text’ activity, insde the UiPath.PDF.Activities Packages.
This will save the data to a text file, you can use regular expressions to extract data from it.
Could you try that?
Let me know if you have any questions?
Hey thank you i will test this out tomorrow. Yes its only text how to make btw the regular expression to take text from the text file from Section 11 to Section 12. From what i understand i first read the pdf than write it to txt file and than use regullar expression to extract only information in from section 11 to section 12.
It sounds that you have a lot of work to do.
The idea of regular expressions is that you find specific parts of the text. You need to find something contant in the docs so you can find your sections
check it out
Please let me know if manage to use it or have any more questions
Thank you so much this one works so i just now need to make it to read all pdf in the folder and create different text file for every pdf. Also to add more regex matches with the different languages of SECTION 11 and SECTION 12.Like for example on German is ABSCHNITT 11 and ABSCHNITT 12 .If you can suggest me how to do this as well will be great.
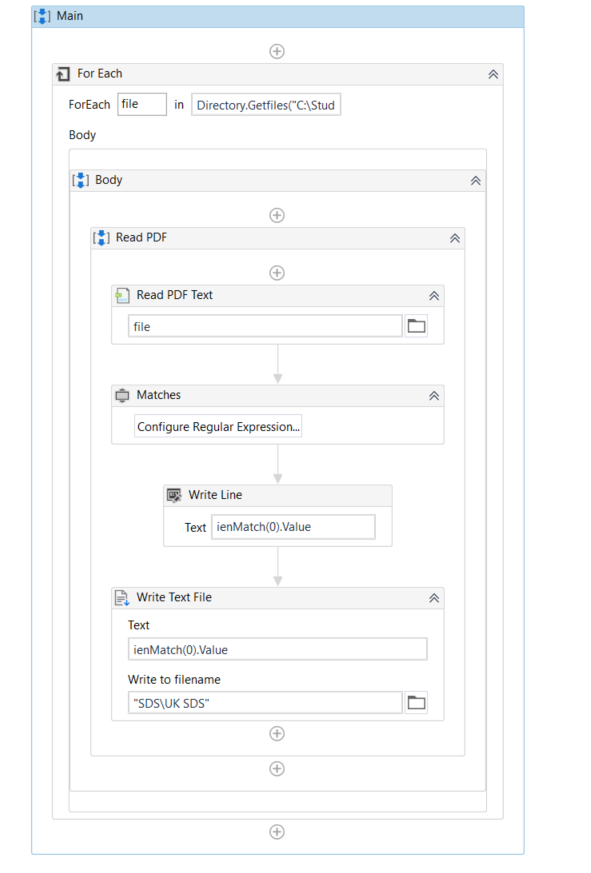
This is the test which i make to check if the regex work and it’s working good it’s taking information only for Section 11 to Section 12 which i need in txt file. Need to create this to check for Section 11 on different languages and checking all pdfs in folder after that extracting the information in different txt file for every pdf.
So i just need to follow this and add all other languages from that i will need to take information to this regular expression and will look for that and if it’s find it will extract it.
Here for example i have 2 pdf files one on English and other one on German , i think it’s reading both since in the output i can see it’s getting information from Section 11 on both languages , but when i check the txt file i see the data only on English , and other one is missing.
Like is reading the first pdf file searching for Section 11 on English which i have already in the regex if it find save it to txt than open the next pdf file which is on German search again for the regex if find save it in txt format.
At all i wanna do it extraction that section 11 on different language for which you guys helped me with the regex i can get that information . I made it to read all pdfs in the folder , but at the end i can’t make it to write separate txt file for each pdf file with the same name as the pdf just txt format with the extracted data from Section 11. Is there a way to make it like If regex find match from the pdf create it as txt and continue on the next file if find a match from the regex which will be in my case next language section 11 create txt file with same name of the pdf.
Hey i think i made it to work atlest it’s working with 3 files and it’s taking information from both languages which i added and getting only Section 11 part i need to test it out for all languages and more pdf.