빈프로세스8.zip (364.7 KB)
안녕하세요. 저는 네이버 금융에서 각 기업의 기본재무정보를 데이터 스크래핑을 이용하여 엑셀로 저장하고자 합니다.
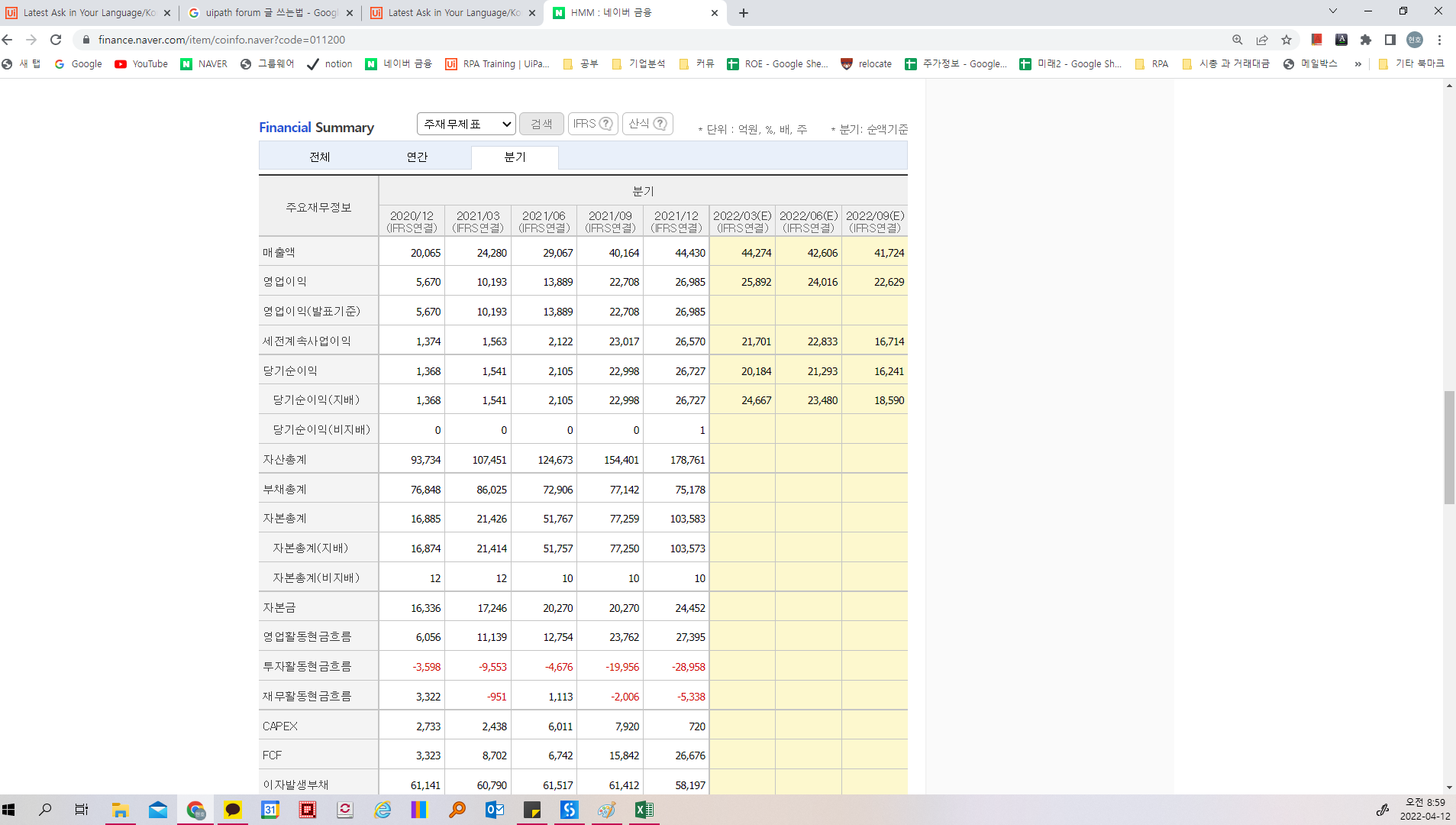
다음과 같이 엑셀 파일의 첫 열에 기업의 이름을 두 번째 열에 기업의 코드가 있습니다.

'For each row in data table’을 사용하여 각 기업명과 기업코드를 받아 인터넷에 검색한 후
데이터 스크래핑을 통해 재무정보를 기업마다 새 시트를 만들어 엑셀로 내보내려고 합니다.
하지만 일부만 잘 작동하고 나머지는 공백으로 남아있거나 같은 값으로 다른 시트가 채워지는 문제가 발생하였습니다.
작동시 각 기업의 재무정보가 담긴 페이지는 잘 열립니다.
데이터 스크래핑이 잘 되지 않는 것 같습니다.
문제의 해결법이나 다른 접근법이 있다면 알려주시면 감사하겠습니다.